Lab #2 : Create Tables
Objectives
The lab teaches you how to work SQL commands to create tables. It requires that you have completed Lab 1 because you will need to edit and run both unit and integration test scripts.
You are provided with scripts that create ten tables. All the tables have dependencies on one another. You generally create tables in a specific order. The order starts with the table that has the least number of dependencies. The second table has the next least number of dependencies and the third through the last follows the same pattern until you get to the table with the most dependencies.
You will work with these ten tables in this and subsequent labs. A single script file should create each table. The SQL script files are unit test programs. Each of the unit test programs writes its own log file.
An eleventh SQL script is an integration script, and it calls all the unit tests. You will download eleven SQL script files for this lab from github.com and put them into a new /lib2 directory in your Linux instance.
After you download and position the script files, you will test them by calling the integration script file. Then, you will copy these unit test programs into the lab2 directory where you will edit each of the unit test scripts to create ten nearly duplicate tables. The last step requires you to copy the base integration program into the lab2 directory where you will edit it to run your modified copies in the lab2 directory.
The lab teaches you how to edit and re-inforces Lab 1 where you learned how to run unit and integration test scripts in SQL*Plus (sqlplus). Working with these scripts should help you learn the following:
- How to edit a unit test script
- How to set a local bind variable
- How to conditionally drop a table
- How to create a table with database constraints
- How to create a sequence for a table’s surrogate primary key
- How to create an index for a table
- How to change the definition of an existing table
- How to query the data dictionary to discover table definitions
Business Scenario
Building data-centric application software requires a place to put the data. You need to create tables to hold the data whether you choose to use a relational, document, or columnar database.
The lab is designed to teach you to create tables in a relational database. Tables should hold a single subject. Well designed tables in domain modeling should include two unique keys, where a unique key is a one or more columns that uniquely define each row in the table. One unique key is a natural key made up of columns that define each instance of data stored in a table. The other unique key is a surrogate key, which is a unique ID. The unique ID is typically populated by a number generated by a sequence that increments by one. The surrogate key acts like an indirect reference to the natural key of the table.
Domain modeling adds the overhead of a surrogate (second unique) key because that key lets you evolve the natural key when you discover that table doesn’t uniquely describe a subject. The natural key provides a set of meaningful information that would let a business user find data about a customer, order, or purchase.
For example, you may want to query a customer by their membership number, credit card number and type, or full name. The following form would let you enter the data to search for the customer.
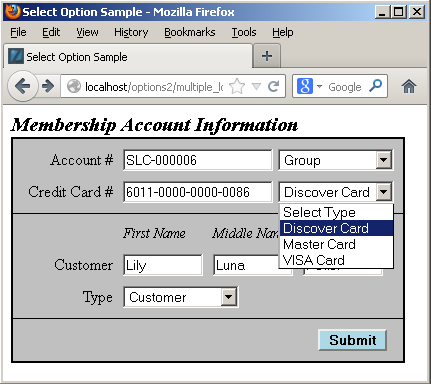
A form like the preceding forms the basis for a query that uses natural key components from more than one table to identify a correct customer record. The customer service team member may query a record like this and then change the customer’s credit card number or type of card fter querying the results. In today’s world, it’s much more likely the customer would query their own data and change their own credit card information.
The customer would never use the surrogate key value because it’s designed to organize table relationships and only meaningful toward resolving queries with natural key data values.
Table design and creation also requires you to identify whether columns are mandatory or optional. Mandatory tables are constrained by a NOT NULL constraint. Optional tables are not constrained, which lets you write a row without a middle name because not everyone has a middle name. Likewise, tables require UNIQUE constraints for the set of columns that defines a table’s natural key; and PRIMARY KEY constraints for surrogate key columns so that you can create FOREIGN KEY constraints to map relationships between rows of data.
Help Section
There are four key elements to creating tables in a relational database. Table names, column names, constraint names, and types are the four key elements of tables.
The name of any table must be unique within a database (a database management system may and typically does hold more than one database). Likewise, column names must be unique within any table. Constraint names are like table names because they must be unique within a database. Lastly, data types must be defined before you use them to create or modify a table definition.
You are asked to review the following preparation material:
- Read the Database Constraints post
NOT NULLConstraintsCHECKConstraintsUNIQUEConstraintsPRIMARY KEYConstraintsFOREIGN KEYConstraints- Read Data Definition Language (DDL) posts
The reading material gives you a foundation of knowledge about creating tables, constraints, indexes, and sequences.
Instructional Material →
The supplemental materials depend on your reading and understanding the preparation material qualified earlier in this lab. The coding segments below show you:
- How to create the
table_namebind variable - How to use the
:table_namebind variable in a conditionalDROPstatement - How to create a
chickentable without any constraints - How to query the structure of the
chickentable with a:table_namebind variable - How to query the constraints of the
chickentable with a:table_namebind variable - How to create a
chicken_ssequence
The instructions walk you through the steps above.
Define a bind variable and assign a value to the bind variable. You define the variable by using a VARIABLE keyword, a table_name identifier, and a VARCHAR2(30) data type. The data type requires that you qualify the length of the string.
You must assign values to bind variables inside PL/SQL anonymous blocks. You must precede a table_name bind variable name with a colon when you want to reference it inside a PL/SQL block.
-- Define a bind variable. VARIABLE table_name VARCHAR2(30) -- Assign an uppercase string to a session bind variable. BEGIN :table_name := UPPER('chicken'); END; / |
You query the value assigned to the table_name bind variable with the following SELECT statement:
SELECT :table_name FROM dual; |
The query returns:
:TABLE_NAME
----------------------
CHICKEN |
chicken table
You can drop a chicken table with the following anonymous PL/SQL program unit:
DECLARE /* Dynamic cursor. */ CURSOR c (cv_object_name VARCHAR2) IS SELECT o.object_type , o.object_name FROM user_objects o WHERE o.object_name LIKE UPPER(cv_object_name||'%'); BEGIN FOR i IN c(:table_name) LOOP IF i.object_type = 'SEQUENCE' THEN EXECUTE IMMEDIATE 'DROP '||i.object_type||' '||i.object_name; ELSIF i.object_type = 'TABLE' THEN EXECUTE IMMEDIATE 'DROP '||i.object_type||' '||i.object_name||' CASCADE CONSTRAINTS'; END IF; END LOOP; END; / |
chicken table
You can create a chicken table without any conditions. The following CREATE statement creates the chicken table:
CREATE TABLE chicken ( chicken_id NUMBER , chicken_name VARCHAR2(20)); |
chicken table definition
You use the following SELECT statement to view the chicken table’s structure:
SET NULL '' COLUMN table_name FORMAT A16 COLUMN column_id FORMAT 9999 COLUMN column_name FORMAT A22 COLUMN data_type FORMAT A12 SELECT table_name , column_id , column_name , CASE WHEN nullable = 'N' THEN 'NOT NULL' ELSE '' END AS nullable , CASE WHEN data_type IN ('CHAR','VARCHAR2','NUMBER') THEN data_type||'('||data_length||')' ELSE data_type END AS data_type FROM user_tab_columns WHERE table_name = 'CHICKEN' ORDER BY 2; |
The query returns:
TABLE_NAME COLUMN_ID COLUMN_NAME NULLABLE DATA_TYPE ---------------- --------- ---------------------- -------- ------------ CHICKEN 1 CHICKEN_ID NUMBER(22) CHICKEN 2 CHICKEN_NAME VARCHAR2(20) |
You have created the chicken table and validated the chicken table’s definition. The instructional material only demonstrates how you create an unconstrained chicken table.
The lab has ten unit testing SQL script files, and one integration SQL script file. Each unit SQL script file contains the steps to manage table creation in a re-runnable script file. The integration SQL script file
Lab Description
[20 points] Click the Lab Instructions link to open the instructions inside the current webpage.
Lab Instructions →
The lab requires that you do the following:
- Create a
lib2subdirectory in the/home/student/Data/cit225/oracledirectory, which you find in maclochlainn/lib2 GitHub repository.mkdir /home/student/Data/cit225/oracle/lib2
- Create a
createsubdirectory in thelib2subdirectorymkdir /home/student/Data/cit225/oracle/lib2/create mkdir /home/student/Data/cit225/oracle/lib2/preseed mkdir /home/student/Data/cit225/oracle/lib2/seed
- Copy all the files from the
create,preseed, andseedGitHub directories to the subdirectories you created in thelib2subdirectory - Copy each unit test file from the
lib2directory to thelab2directory by adding_LABsuffix to the file namecp /home/student/Data/cit225/oracle/lib2/create/system_user.sql /home/student/Data/cit225/oracle/lib2/create/system_user_lab.sql cp /home/student/Data/cit225/oracle/lib2/create/common_lookup.sql /home/student/Data/cit225/oracle/lib2/create/common_lookup_lab.sql cp /home/student/Data/cit225/oracle/lib2/create/member.sql /home/student/Data/cit225/oracle/lib2/create/member_lab.sql cp /home/student/Data/cit225/oracle/lib2/create/contact.sql /home/student/Data/cit225/oracle/lib2/create/contact_lab.sql cp /home/student/Data/cit225/oracle/lib2/create/address.sql /home/student/Data/cit225/oracle/lib2/create/address_lab.sql cp /home/student/Data/cit225/oracle/lib2/create/street_address.sql /home/student/Data/cit225/oracle/lib2/create/street_address_lab.sql cp /home/student/Data/cit225/oracle/lib2/create/telephone.sql /home/student/Data/cit225/oracle/lib2/create/telephone_lab.sql cp /home/student/Data/cit225/oracle/lib2/create/item.sql /home/student/Data/cit225/oracle/lib2/create/item_lab.sql cp /home/student/Data/cit225/oracle/lib2/create/rental.sql /home/student/Data/cit225/oracle/lib2/create/rental_lab.sql cp /home/student/Data/cit225/oracle/lib2/create/rental_item.sql /home/student/Data/cit225/oracle/lib2/create/rental_item_lab.sql
- Edit each unit test file to create mirrored tables with an
_LABsuffix - Edit each unit test file by changing all of the
_IDsuffix columns to_LAB_IDsuffix columns - Copy the integration file from the
lib2directory to thelab2directorycp /home/student/Data/cit225/oracle/lib2/create/create_oracle_store2.sql /home/student/Data/cit225/oracle/lib2/create/integration.sql
- Edit the integration file by changing all the script references to the new file name
Please perform the following tasks:
You begin these steps by running the cleanup_oracle.sql and create_oracle_store2.sql scripts. A great starting point for this lab is to review the create_oracle_store2.sql script. The create_oracle_store2.sql script creates 10 tables. Your Lab #2 script creates 10 tables with some changes and alterations.
You should use the script provided in the downloaded instance or create a new integration script, like the following:
-- Run the prior lab script. @/home/student/Data/cit225/oracle/lib/cleanup_oracle.sql @/home/student/Data/cit225/oracle/lib2/create_oracle_store2.sql -- ... insert calls to other files with code here, like ... @@system_user_lab.sql SPOOL apply_oracle_lab2.txt -- ... insert your code here ... SPOOL OFF |
You should embed the verification queries inside your apply_lab2_oracle.sql script.
- [0 points] Tutorial on creating the
SYSTEM_USER_LABtable and theSYSTEM_USER_LAB_S1sequence, which is Step #1. The reasons for making the changes are:- Table, sequence, and constraint names are unique inside a schema or database.
- All the tables, sequences, and constraints names must have counterparts that use an
_LABsuffix or an_LAB_between the base table constraint name and its number.
SYSTEM_USER_LAB table, you repeat the process by copying segments and editing them until you replicate the entire create_oracle_store.sql script for tables with the _LAB suffix or an _LAB_ element between the base table constraint name and its number.
Tutorial Details ↓
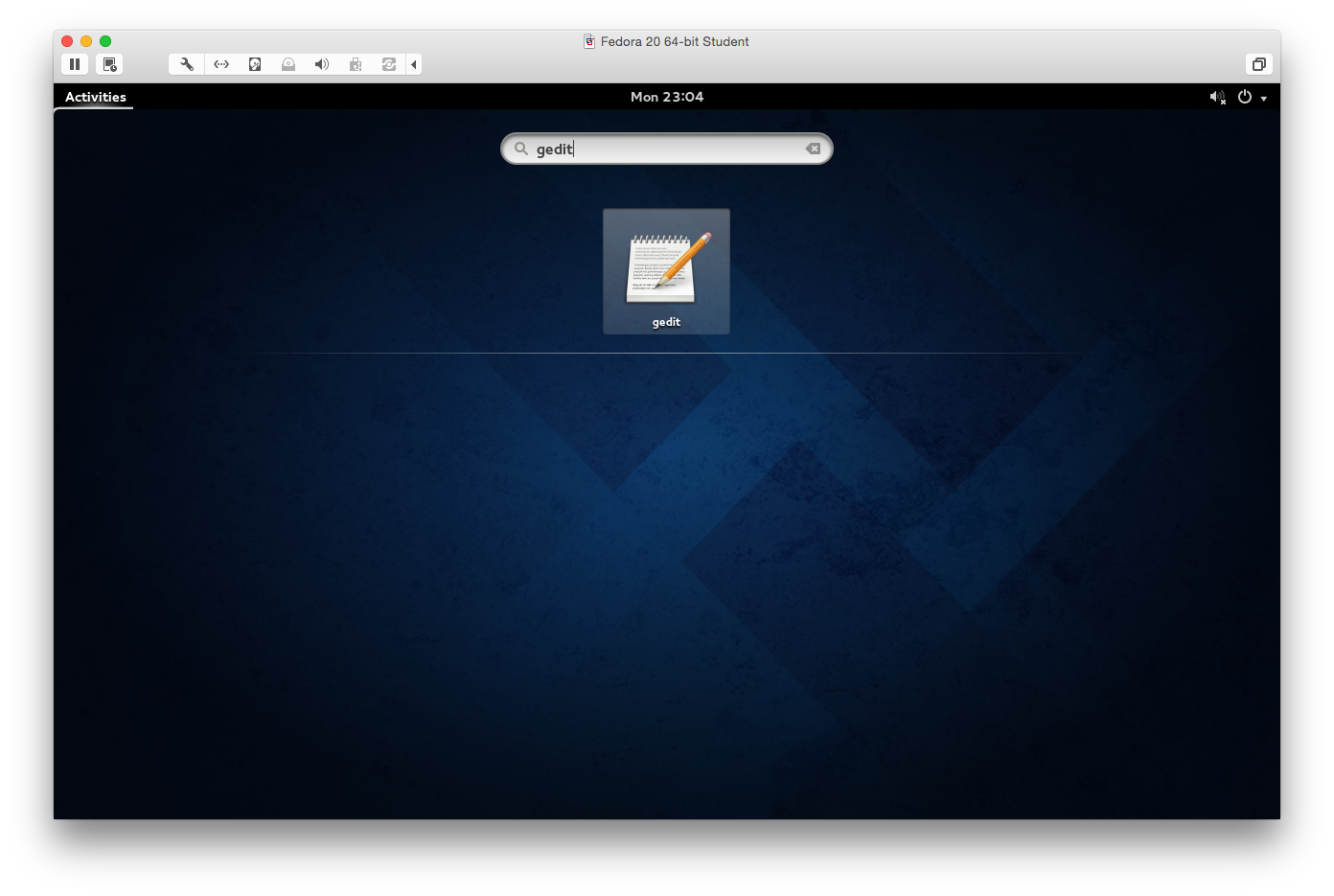
- You connect to the VMware instance as the
studentuser. Then, click on Activities to launch the menu. Entergeditin the search box and click the Return key to launch thegeditprogram.
- Having launched the
geditapplication, you should see the following image. Click the Open button to find and open thecreate_oracle_store.sqlfile.
- Having opened the File Manager dialog, you can now click on the Home option in the Places list on the left.
- Double click on the Data folder in the Name list.
- After double clicking on the Data folder, the File Manager opens the Data folder and puts the Data folder in the list of folders. Next, click on the cit225 folder the Name list.
- After double clicking on the cit225 folder, the File Manager opens the cit225 folder and puts the cit225 folder in the list of folders. Next, click on the oracle folder the Name list.
- After double clicking on the oracle folder, the File Manager opens the oracle folder and puts the oracle folder in the list of folders. Next, click on the lib folder the Name list.
- After double clicking on the lib folder, the File Manager opens the lib folder and puts the lib folder in the list of folders. Next, click on the Open button to open the
create_oracle_store.sqlfile in thegeditapplication.
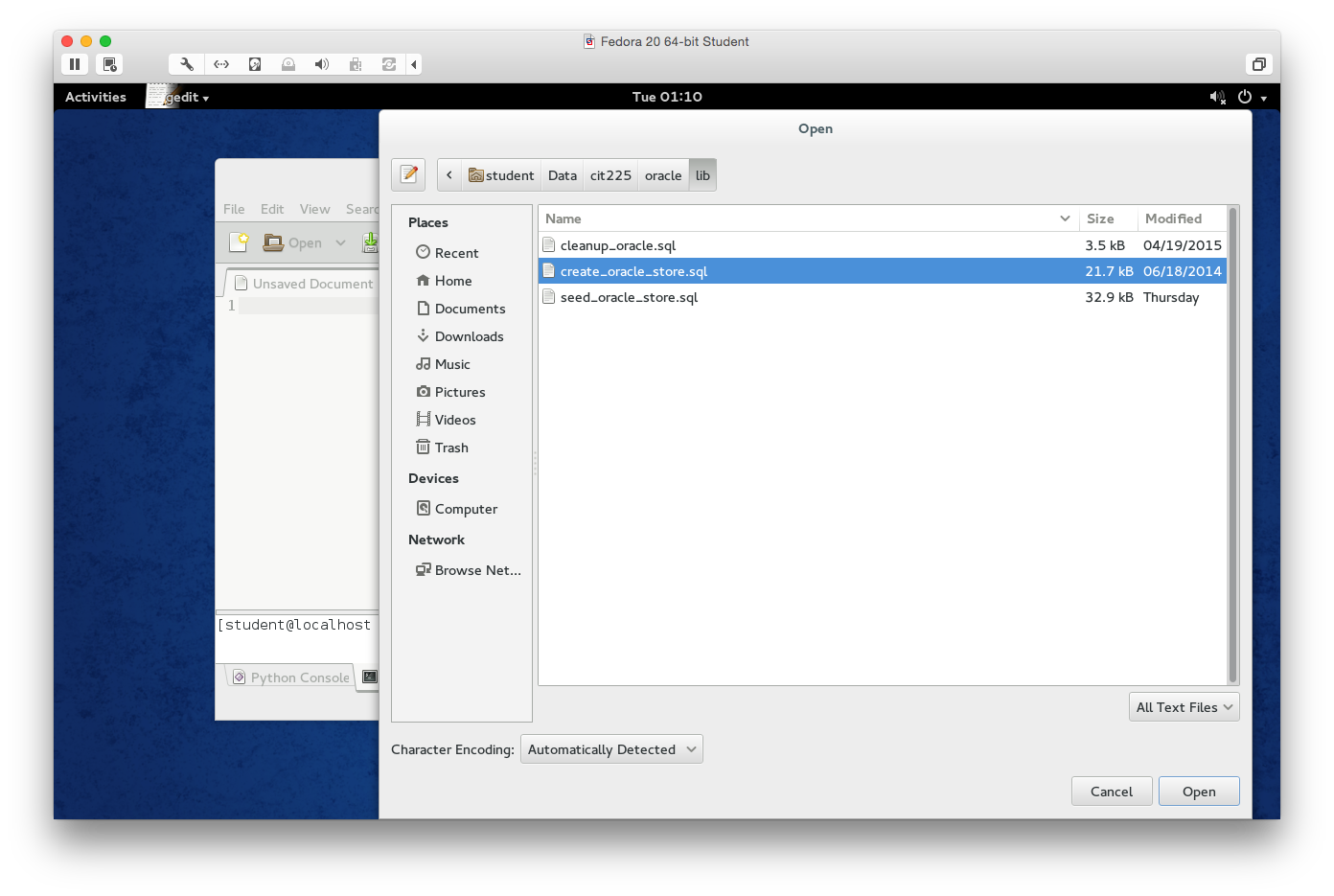
- You should see the following
create_oracle_store.sqlscript in thegeditapplication.
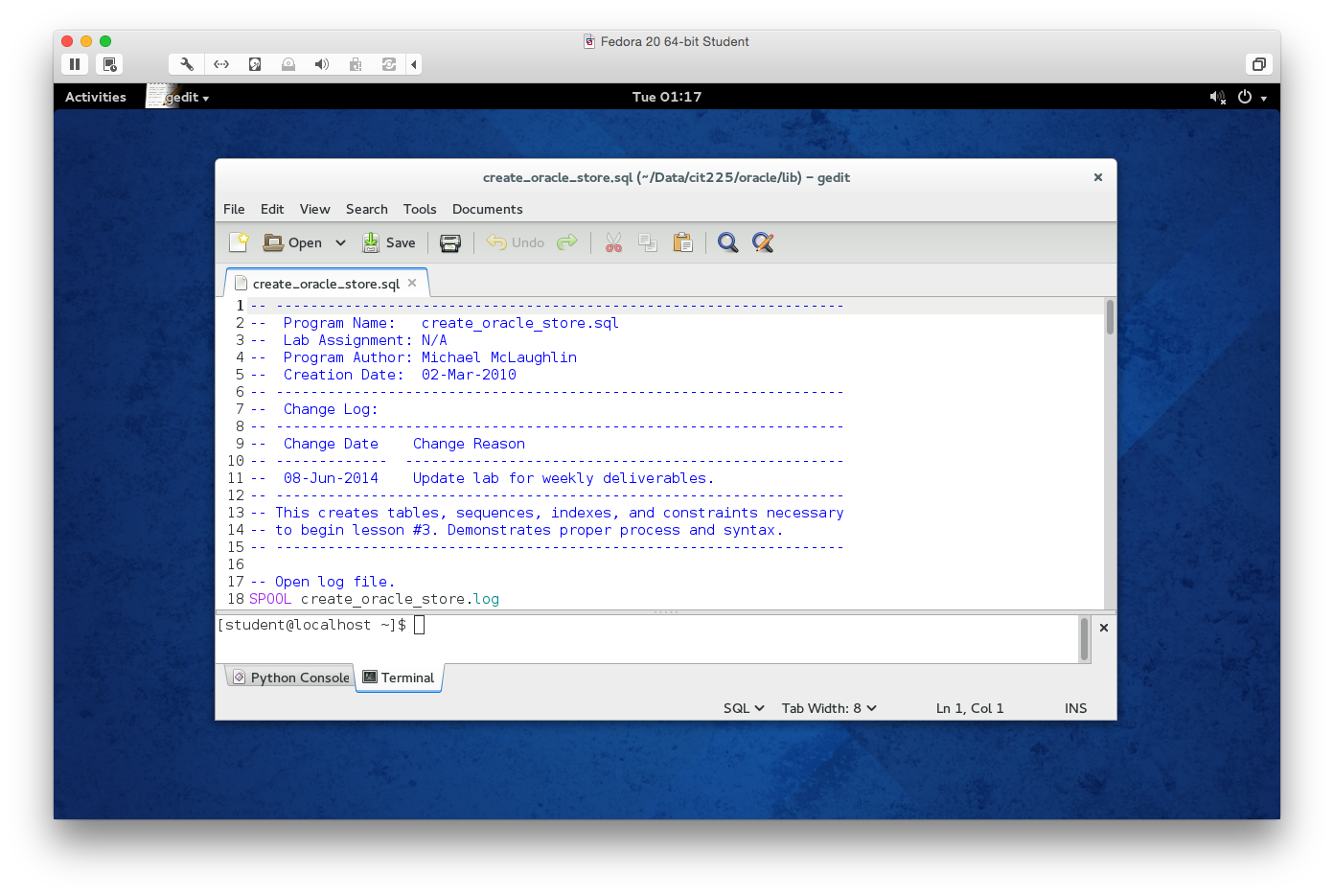
- After opening the
create_oracle_store.sqlscript, click on the oracle button in the file path above the panes. Then, click on thelibfolder. You will see theapply_oracle_lab2.sqlfile. Click the Open button to open theapply_oracle_lab2.sqlfile in thegeditfile.
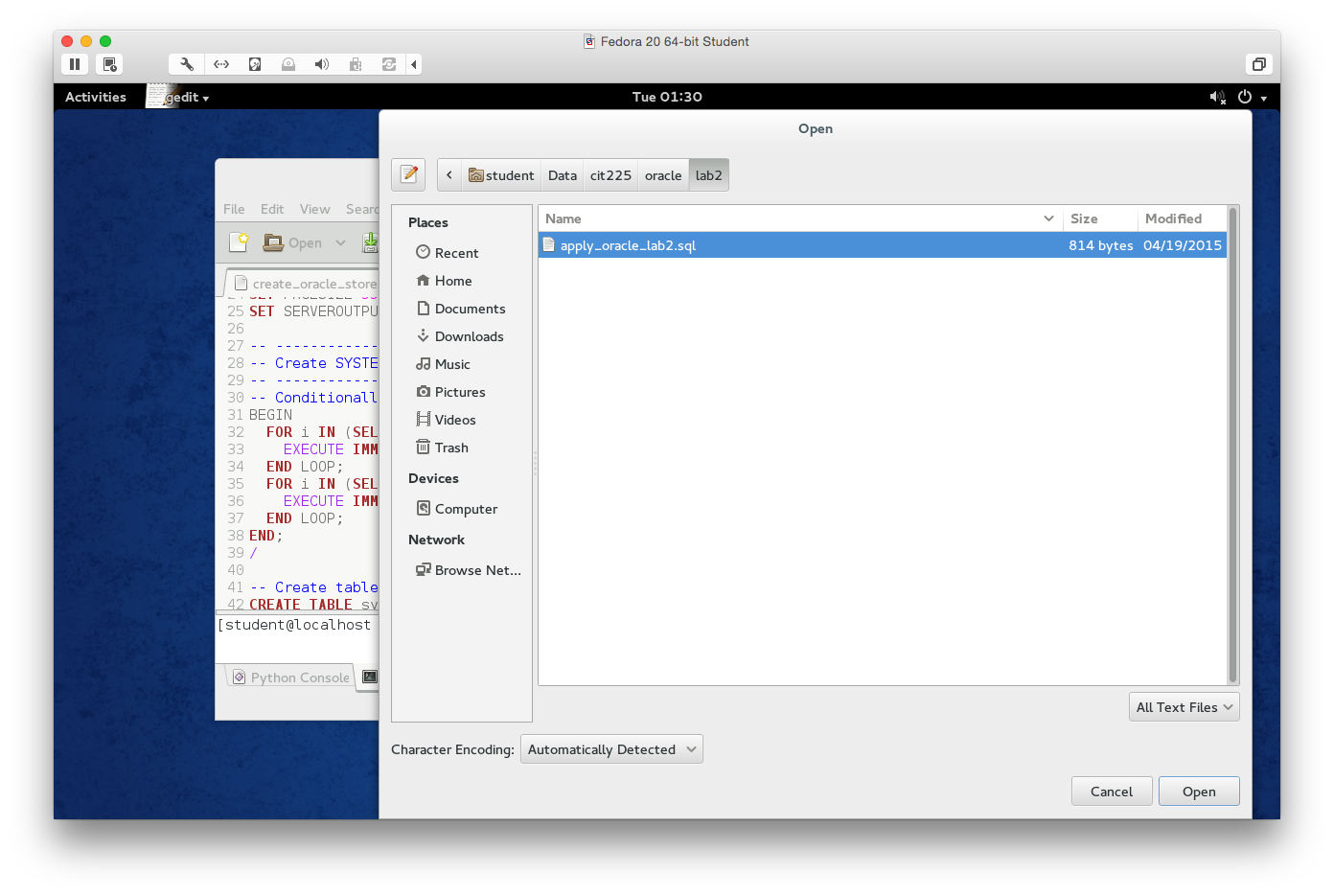
- You should see the following
apply_oracle_lab2.sqlscript in thegeditapplication. You should only edit below the last line, which means don’t change anything above the last comment line.
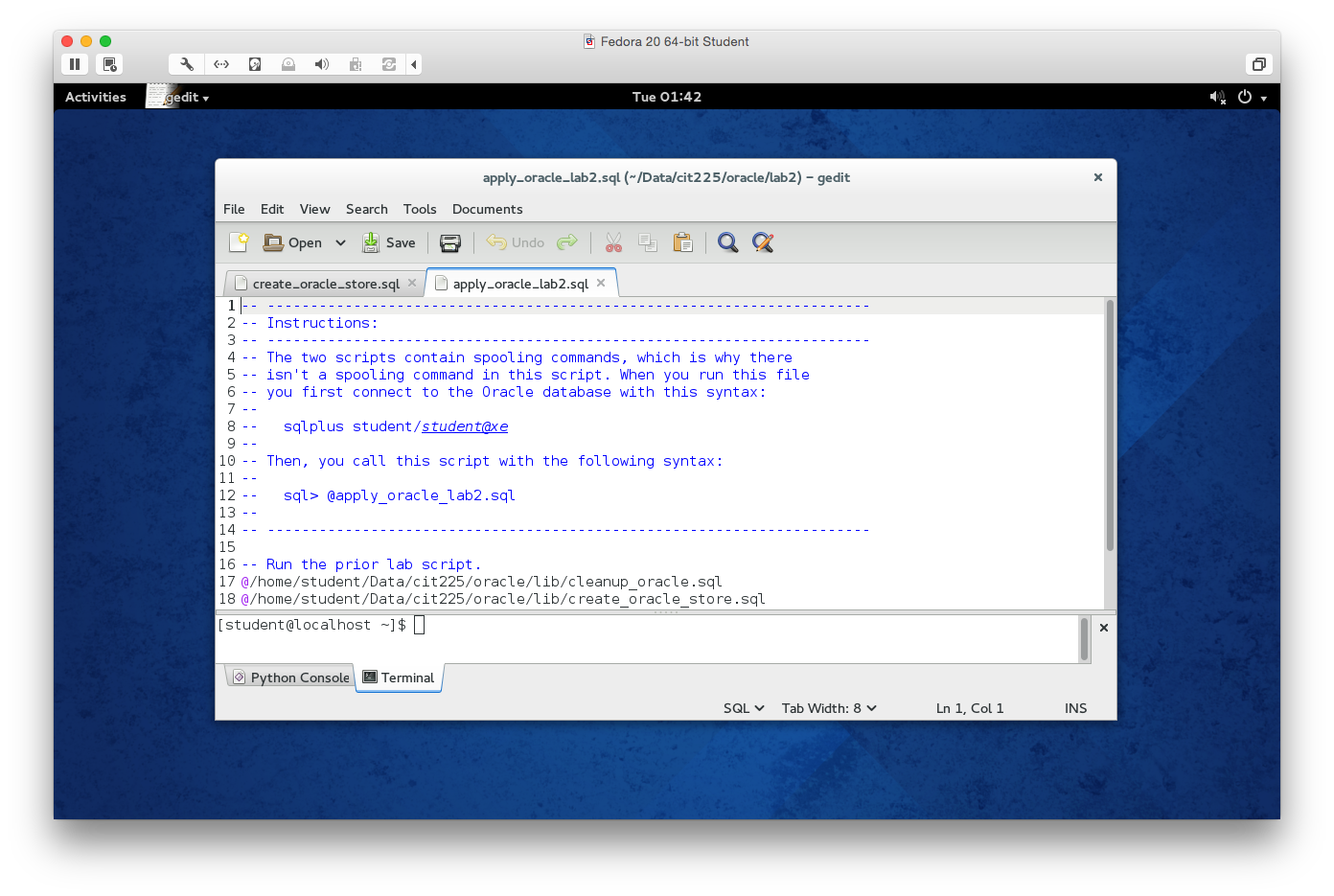
- You should see the following
apply_oracle_lab2.sqlscript in thegeditapplication. You should only edit below the last line, which means don’t change anything above the last comment line.
- Copy the content from line 27 to 79 from the create_oracle_store.sql script and paste it to lines 23 through 75. Then, make the following changes:
- Change all uppercase references to
SYSTEM_USERtoSYSTEM_USER_LAB. - Change all lowercase references to
system_usertosystem_user_lab. - Change all constraint names from
nn_system_user_xtonn_system_user_lab_x. - Change all lowercase references to
fk_system_user_xtofk_system_user_lab_x.
- Change all uppercase references to
- After you make the changes to the script, you need to copy the confirmation queries from the Instruction Details of tasks 1 through 12 (below) into your
apply_oracle_lab2.sqlscript. Then, you need to run it and verify that you have the same output as the web page.
- [2 points] Create the
SYSTEM_USER_LABtable described by the following and theSYSTEM_USER_LAB_S1sequence starting with a value of1001:
Instruction Details ↓
| Table Name: SYSTEM_USER_LAB | |||||
|---|---|---|---|---|---|
| Column Name | Constraint | Data Type |
Physical Size |
||
| Type | Reference Table | Reference Column | |||
| SYSTEM_USER_LAB_ID | PRIMARY KEY | Integer | Maximum | ||
| SYSTEM_USER_NAME | NOT NULL | String | 20 | ||
| SYSTEM_USER_GROUP_ID | FOREIGN KEY | COMMON_LOOKUP_LAB | COMMON_LOOKUP_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| SYSTEM_USER_TYPE | FOREIGN KEY | COMMON_LOOKUP_LAB | COMMON_LOOKUP_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| FIRST_NAME | String | 20 | |||
| MIDDLE_NAME | String | 20 | |||
| LAST_NAME | String | 20 | |||
| CREATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| CREATION_DATE | NOT NULL | DATE | Date | ||
| LAST_UPDATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| LAST_UPDATE_DATE | NOT NULL | DATE | Date | ||
You should use the following formatting and query to verify completion of this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | SET NULL '' COLUMN table_name FORMAT A16 COLUMN column_id FORMAT 9999 COLUMN column_name FORMAT A22 COLUMN data_type FORMAT A12 SELECT table_name , column_id , column_name , CASE WHEN nullable = 'N' THEN 'NOT NULL' ELSE '' END AS nullable , CASE WHEN data_type IN ('CHAR','VARCHAR2','NUMBER') THEN data_type||'('||data_length||')' ELSE data_type END AS data_type FROM user_tab_columns WHERE table_name = 'SYSTEM_USER_LAB' ORDER BY 2; |
It should display the following results:
TABLE_NAME COLUMN_ID COLUMN_NAME NULLABLE DATA_TYPE ---------------- --------- ---------------------- -------- ------------ SYSTEM_USER_LAB 1 SYSTEM_USER_LAB_ID NOT NULL NUMBER(22) SYSTEM_USER_LAB 2 SYSTEM_USER_NAME NOT NULL VARCHAR2(20) SYSTEM_USER_LAB 3 SYSTEM_USER_GROUP_ID NOT NULL NUMBER(22) SYSTEM_USER_LAB 4 SYSTEM_USER_TYPE NOT NULL NUMBER(22) SYSTEM_USER_LAB 5 FIRST_NAME VARCHAR2(20) SYSTEM_USER_LAB 6 MIDDLE_NAME VARCHAR2(20) SYSTEM_USER_LAB 7 LAST_NAME VARCHAR2(20) SYSTEM_USER_LAB 8 CREATED_BY NOT NULL NUMBER(22) SYSTEM_USER_LAB 9 CREATION_DATE NOT NULL DATE SYSTEM_USER_LAB 10 LAST_UPDATED_BY NOT NULL NUMBER(22) SYSTEM_USER_LAB 11 LAST_UPDATE_DATE NOT NULL DATE 11 rows selected. |
You should use the following formatting and query to verify completion of the constraints for this step:
1 2 3 4 5 6 7 8 9 10 11 12 | COLUMN constraint_name FORMAT A22 COLUMN search_condition FORMAT A36 COLUMN constraint_type FORMAT A1 SELECT uc.constraint_name , uc.search_condition , uc.constraint_type FROM user_constraints uc INNER JOIN user_cons_columns ucc ON uc.table_name = ucc.table_name AND uc.constraint_name = ucc.constraint_name WHERE uc.table_name = UPPER('system_user_lab') AND uc.constraint_type = UPPER('c') ORDER BY uc.constraint_name; |
It should display the following results:
CONSTRAINT_NAME SEARCH_CONDITION C ---------------------- ------------------------------------ - NN_SYSTEM_USER_LAB_1 "SYSTEM_USER_NAME" IS NOT NULL C NN_SYSTEM_USER_LAB_2 "SYSTEM_USER_GROUP_ID" IS NOT NULL C NN_SYSTEM_USER_LAB_3 "SYSTEM_USER_TYPE" IS NOT NULL C NN_SYSTEM_USER_LAB_4 "CREATED_BY" IS NOT NULL C NN_SYSTEM_USER_LAB_5 "CREATION_DATE" IS NOT NULL C NN_SYSTEM_USER_LAB_6 "LAST_UPDATED_BY" IS NOT NULL C NN_SYSTEM_USER_LAB_7 "LAST_UPDATE_DATE" IS NOT NULL C 7 rows selected. |
You can validate that you created the two self-referencing foreign key constraints with the following query:
COL constraint_source FORMAT A38 HEADING "Constraint Name:| Table.Column" COL references_column FORMAT A40 HEADING "References:| Table.Column" SELECT uc.constraint_name||CHR(10) || '('||ucc1.table_name||'.'||ucc1.column_name||')' constraint_source , 'REFERENCES'||CHR(10) || '('||ucc2.table_name||'.'||ucc2.column_name||')' references_column FROM user_constraints uc , user_cons_columns ucc1 , user_cons_columns ucc2 WHERE uc.constraint_name = ucc1.constraint_name AND uc.r_constraint_name = ucc2.constraint_name AND ucc1.POSITION = ucc2.POSITION -- Correction for multiple column primary keys. AND uc.constraint_type = 'R' AND ucc1.table_name = 'SYSTEM_USER_LAB' ORDER BY ucc1.table_name , uc.constraint_name; |
It should display only the following:
Constraint Name: References: Table.Column Table.Column -------------------------------------- ------------------------------------------ FK_SYSTEM_USER_LAB_1 REFERENCES (SYSTEM_USER_LAB.CREATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) FK_SYSTEM_USER_LAB_2 REFERENCES (SYSTEM_USER_LAB.LAST_UPDATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) |
Please note that the foreign keys on the SYSTEM_USER_GROUP_ID and SYSTEM_USER_TYPE columns haven’t been created at this point. That’s because they can’t exists until you create the COMMON_LOOKUP_LAB table.
You should then create a UQ_SYSTEM_USER_LAB_1 unique index on the SYSTEM_USER_NAME column of the SYSTEM_USER_LAB table. You can then use this query to display the unique constants on the table:
COLUMN index_name FORMAT A20 HEADING "Index Name" SELECT index_name FROM user_indexes WHERE table_name = UPPER('system_user_lab'); |
It should display:
Index Name -------------------- PK_SYSTEM_USER_LAB_1 UQ_SYSTEM_USER_LAB_1 |
You can verify the existence of the SYSTEM_USER_LAB_S1 sequence with the following query:
COLUMN sequence_name FORMAT A20 HEADING "Sequence Name" SELECT sequence_name FROM user_sequences WHERE sequence_name = UPPER('system_user_lab_s1'); |
It should display the following:
Sequence Name -------------------- SYSTEM_USER_LAB_S1 1 row selected. |
- [2 points] Create the
COMMON_LOOKUP_LABtable described by the following and theCOMMON_LOOKUP_LAB_S1sequence starting with a value of1001:
Instruction Details ↓
| Table Name: COMMON_LOOKUP_LAB | |||||
|---|---|---|---|---|---|
| Column Name | Constraint | Data Type |
Physical Size |
||
| Type | Reference Table | Reference Column | |||
| COMMON_LOOKUP_LAB_ID | PRIMARY KEY | Integer | Maximum | ||
| COMMON_LOOKUP_CONTEXT | NOT NULL | String | 30 | ||
| COMMON_LOOKUP_TYPE | NOT NULL | String | 30 | ||
| COMMON_LOOKUP_MEANING | NOT NULL | String | 30 | ||
| CREATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| CREATION_DATE | NOT NULL | DATE | Date | ||
| LAST_UPDATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| LAST_UPDATE_DATE | NOT NULL | DATE | Date | ||
You should use the following formatting and query to verify completion of this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | SET NULL '' COLUMN table_name FORMAT A18 COLUMN column_id FORMAT 9999 COLUMN column_name FORMAT A22 COLUMN data_type FORMAT A12 SELECT table_name , column_id , column_name , CASE WHEN nullable = 'N' THEN 'NOT NULL' ELSE '' END AS nullable , CASE WHEN data_type IN ('CHAR','VARCHAR2','NUMBER') THEN data_type||'('||data_length||')' ELSE data_type END AS data_type FROM user_tab_columns WHERE table_name = 'COMMON_LOOKUP_LAB' ORDER BY 2; |
It should display the following results:
TABLE_NAME COLUMN_ID COLUMN_NAME NULLABLE DATA_TYPE ------------------ --------- ---------------------- -------- ------------ COMMON_LOOKUP_LAB 1 COMMON_LOOKUP_LAB_ID NOT NULL NUMBER(22) COMMON_LOOKUP_LAB 2 COMMON_LOOKUP_CONTEXT NOT NULL VARCHAR2(30) COMMON_LOOKUP_LAB 3 COMMON_LOOKUP_TYPE NOT NULL VARCHAR2(30) COMMON_LOOKUP_LAB 4 COMMON_LOOKUP_MEANING NOT NULL VARCHAR2(30) COMMON_LOOKUP_LAB 5 CREATED_BY NOT NULL NUMBER(22) COMMON_LOOKUP_LAB 6 CREATION_DATE NOT NULL DATE COMMON_LOOKUP_LAB 7 LAST_UPDATED_BY NOT NULL NUMBER(22) COMMON_LOOKUP_LAB 8 LAST_UPDATE_DATE NOT NULL DATE 8 rows selected. |
You should use the following formatting and query to verify completion of the constraints for this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 | COLUMN constraint_name FORMAT A22 COLUMN search_condition FORMAT A36 COLUMN constraint_type FORMAT A1 SELECT uc.constraint_name , uc.search_condition , uc.constraint_type FROM user_constraints uc INNER JOIN user_cons_columns ucc ON uc.table_name = ucc.table_name AND uc.constraint_name = ucc.constraint_name WHERE uc.table_name = UPPER('common_lookup_lab') AND uc.constraint_type IN (UPPER('c'),UPPER('p')) ORDER BY uc.constraint_type DESC , uc.constraint_name; |
It should display the following results:
CONSTRAINT_NAME SEARCH_CONDITION C ---------------------- ------------------------------------ - PK_CLOOKUP_LAB_1 P NN_CLOOKUP_LAB_1 "COMMON_LOOKUP_CONTEXT" IS NOT NULL C NN_CLOOKUP_LAB_2 "COMMON_LOOKUP_TYPE" IS NOT NULL C NN_CLOOKUP_LAB_3 "COMMON_LOOKUP_MEANING" IS NOT NULL C NN_CLOOKUP_LAB_4 "CREATED_BY" IS NOT NULL C NN_CLOOKUP_LAB_5 "CREATION_DATE" IS NOT NULL C NN_CLOOKUP_LAB_6 "LAST_UPDATED_BY" IS NOT NULL C NN_CLOOKUP_LAB_7 "LAST_UPDATE_DATE" IS NOT NULL C 8 rows selected. |
You can validate that you created the two foreign key constraints with the following query:
COL constraint_source FORMAT A38 HEADING "Constraint Name:| Table.Column" COL references_column FORMAT A40 HEADING "References:| Table.Column" SELECT uc.constraint_name||CHR(10) || '('||ucc1.table_name||'.'||ucc1.column_name||')' constraint_source , 'REFERENCES'||CHR(10) || '('||ucc2.table_name||'.'||ucc2.column_name||')' references_column FROM user_constraints uc , user_cons_columns ucc1 , user_cons_columns ucc2 WHERE uc.constraint_name = ucc1.constraint_name AND uc.r_constraint_name = ucc2.constraint_name AND ucc1.POSITION = ucc2.POSITION -- Correction for multiple column primary keys. AND uc.constraint_type = 'R' AND ucc1.table_name = 'COMMON_LOOKUP_LAB' ORDER BY ucc1.table_name , uc.constraint_name; |
It should display only the following:
Constraint Name: References: Table.Column Table.Column -------------------------------------- ----------------------------------------- FK_CLOOKUP_LAB_1 REFERENCES (COMMON_LOOKUP_LAB.CREATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) FK_CLOOKUP_LAB_2 REFERENCES (COMMON_LOOKUP_LAB.LAST_UPDATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) |
You should then create a unique COMMON_LOOKUP_LAB_U1 unique index on the COMMON_LOOKUP_CONTEXT and COMMON_LOOKUP_TYPE columns of the COMMON_LOOKUP table; and a non-unique COMMON_LOOKUP_LAB_N1 index on the COMMON_LOOKUP_CONTEXT column of the COMMON_LOOKUP table:
COLUMN sequence_name FORMAT A22 HEADING "Sequence Name" COLUMN column_position FORMAT 999 HEADING "Column|Position" COLUMN column_name FORMAT A22 HEADING "Column|Name" SELECT UI.index_name , uic.column_position , uic.column_name FROM user_indexes UI INNER JOIN user_ind_columns uic ON UI.index_name = uic.index_name AND UI.table_name = uic.table_name WHERE UI.table_name = UPPER('common_lookup_lab') ORDER BY UI.index_name , uic.column_position; |
It should display:
Column Column Index Name Position Name -------------------- -------- ---------------------- COMMON_LOOKUP_LAB_1 1 COMMON_LOOKUP_LAB_ID COMMON_LOOKUP_LAB_N1 1 COMMON_LOOKUP_CONTEXT COMMON_LOOKUP_LAB_U1 1 COMMON_LOOKUP_CONTEXT COMMON_LOOKUP_LAB_U1 2 COMMON_LOOKUP_TYPE |
You add two new foreign keys to the SYSTEM_USER_LAB table. They should:
- Add a
FK_SYSTEM_USER_3foreign key to theSYSTEM_USER_LABtable. It should be placed on on theSYSTEM_USER_GROUP_IDcolumn of theSYSTEM_USER_LABtable; and it should reference theCOMMON_LOOKUP_LAB_IDcolumn of theCOMMON_LOOKUP_LABtable. - Add a
FK_SYSTEM_USER_4foreign key to theSYSTEM_USER_LABtable. It should be placed on on theSYSTEM_USER_TYPEcolumn of theSYSTEM_USER_LABtable; and it should reference theCOMMON_LOOKUP_LAB_IDcolumn of theCOMMON_LOOKUP_LABtable.
Run the following query after you add the new foreign key constraints.
COL constraint_source FORMAT A38 HEADING "Constraint Name:| Table.Column" COL references_column FORMAT A40 HEADING "References:| Table.Column" SELECT uc.constraint_name||CHR(10) || '('||ucc1.table_name||'.'||ucc1.column_name||')' constraint_source , 'REFERENCES'||CHR(10) || '('||ucc2.table_name||'.'||ucc2.column_name||')' references_column FROM user_constraints uc , user_cons_columns ucc1 , user_cons_columns ucc2 WHERE uc.constraint_name = ucc1.constraint_name AND uc.r_constraint_name = ucc2.constraint_name AND ucc1.position = ucc2.position -- Correction for multiple column primary keys. AND uc.constraint_type = 'R' AND ucc1.table_name = 'SYSTEM_USER_LAB' ORDER BY ucc1.table_name , uc.constraint_name; |
It should show you the following:
Constraint Name: References: Table.Column Table.Column -------------------------------------- ---------------------------------------- FK_SYSTEM_USER_1 REFERENCES (SYSTEM_USER.CREATED_BY) (SYSTEM_USER.SYSTEM_USER_ID) FK_SYSTEM_USER_2 REFERENCES (SYSTEM_USER.LAST_UPDATED_BY) (SYSTEM_USER.SYSTEM_USER_ID) FK_SYSTEM_USER_3 REFERENCES (SYSTEM_USER.SYSTEM_USER_GROUP_ID) (COMMON_LOOKUP.COMMON_LOOKUP_ID) FK_SYSTEM_USER_4 REFERENCES (SYSTEM_USER.SYSTEM_USER_TYPE) (COMMON_LOOKUP.COMMON_LOOKUP_ID) |
You can verify the existence of the COMMON_LOOKUP_LAB_S1 sequence with the following query:
COLUMN sequence_name FORMAT A20 HEADING "Sequence Name" SELECT sequence_name FROM user_sequences WHERE sequence_name = UPPER('common_lookup_lab_s1'); |
It should display the following:
Sequence Name -------------------- COMMON_LOOKUP_LAB_S1 1 row selected. |
- [2 points] Create the
MEMBER_LABtable described by the following and theMEMBER_LAB_S1sequence starting with a value of1001:
Instruction Details ↓
| Table Name: MEMBER_LAB | |||||
|---|---|---|---|---|---|
| Column Name | Constraint | Data Type |
Physical Size |
||
| Type | Reference Table | Reference Column | |||
| MEMBER_LAB_ID | PRIMARY KEY | Integer | Maximum | ||
| MEMBER_TYPE | FOREIGN KEY | COMMON_LOOKUP_LAB | COMMON_LOOKUP_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| ACCOUNT_NUMBER | NOT NULL | String | 10 | ||
| CREDIT_CARD_NUMBER | NOT NULL | String | 20 | ||
| CREDIT_CARD_TYPE | FOREIGN KEY | COMMON_LOOKUP_LAB | COMMON_LOOKUP_ID | Integer | Maximum |
| NOT NULL | |||||
| CREATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| CREATION_DATE | NOT NULL | DATE | Date | ||
| LAST_UPDATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| LAST_UPDATE_DATE | NOT NULL | DATE | Date | ||
You should use the following formatting and query to verify completion of this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | SET NULL '' COLUMN table_name FORMAT A18 COLUMN column_id FORMAT 9999 COLUMN column_name FORMAT A22 COLUMN data_type FORMAT A12 SELECT table_name , column_id , column_name , CASE WHEN nullable = 'N' THEN 'NOT NULL' ELSE '' END AS nullable , CASE WHEN data_type IN ('CHAR','VARCHAR2','NUMBER') THEN data_type||'('||data_length||')' ELSE data_type END AS data_type FROM user_tab_columns WHERE table_name = 'MEMBER_LAB' ORDER BY 2; |
It should display the following results:
TABLE_NAME COLUMN_ID COLUMN_NAME NULLABLE DATA_TYPE ------------------ --------- ---------------------- -------- ------------ MEMBER_LAB 1 MEMBER_LAB_ID NOT NULL NUMBER(22) MEMBER_LAB 2 MEMBER_TYPE NOT NULL NUMBER(22) MEMBER_LAB 3 ACCOUNT_NUMBER NOT NULL VARCHAR2(10) MEMBER_LAB 4 CREDIT_CARD_NUMBER NOT NULL VARCHAR2(19) MEMBER_LAB 5 CREDIT_CARD_TYPE NOT NULL NUMBER(22) MEMBER_LAB 6 CREATED_BY NOT NULL NUMBER(22) MEMBER_LAB 7 CREATION_DATE NOT NULL DATE MEMBER_LAB 8 LAST_UPDATED_BY NOT NULL NUMBER(22) MEMBER_LAB 9 LAST_UPDATE_DATE NOT NULL DATE 9 rows selected. |
You should use the following formatting and query to verify completion of the constraints for this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 | COLUMN constraint_name FORMAT A22 COLUMN search_condition FORMAT A36 COLUMN constraint_type FORMAT A1 SELECT uc.constraint_name , uc.search_condition , uc.constraint_type FROM user_constraints uc INNER JOIN user_cons_columns ucc ON uc.table_name = ucc.table_name AND uc.constraint_name = ucc.constraint_name WHERE uc.table_name = UPPER('member_lab') AND uc.constraint_type IN (UPPER('c'),UPPER('p')) ORDER BY uc.constraint_type DESC , uc.constraint_name; |
It should display the following results:
CONSTRAINT_NAME SEARCH_CONDITION C ---------------------- ------------------------------------ - PK_MEMBER_LAB_1 P NN_MEMBER_LAB_1 "MEMBER_TYPE" IS NOT NULL C NN_MEMBER_LAB_2 "ACCOUNT_NUMBER" IS NOT NULL C NN_MEMBER_LAB_3 "CREDIT_CARD_NUMBER" IS NOT NULL C NN_MEMBER_LAB_4 "CREDIT_CARD_TYPE" IS NOT NULL C NN_MEMBER_LAB_5 "CREATED_BY" IS NOT NULL C NN_MEMBER_LAB_6 "CREATION_DATE" IS NOT NULL C NN_MEMBER_LAB_7 "LAST_UPDATED_BY" IS NOT NULL C NN_MEMBER_LAB_8 "LAST_UPDATE_DATE" IS NOT NULL C 9 rows selected. |
You can validate that you created the four foreign key constraints with the following query:
COL constraint_source FORMAT A38 HEADING "Constraint Name:| Table.Column" COL references_column FORMAT A40 HEADING "References:| Table.Column" SELECT uc.constraint_name||CHR(10) || '('||ucc1.table_name||'.'||ucc1.column_name||')' constraint_source , 'REFERENCES'||CHR(10) || '('||ucc2.table_name||'.'||ucc2.column_name||')' references_column FROM user_constraints uc , user_cons_columns ucc1 , user_cons_columns ucc2 WHERE uc.constraint_name = ucc1.constraint_name AND uc.r_constraint_name = ucc2.constraint_name AND ucc1.POSITION = ucc2.POSITION -- Correction for multiple column primary keys. AND uc.constraint_type = 'R' AND ucc1.table_name = 'MEMBER_LAB' ORDER BY ucc1.table_name , uc.constraint_name; |
It should display only the following:
Constraint Name: References: Table.Column Table.Column -------------------------------------- ----------------------------------------- FK_MEMBER_LAB_1 REFERENCES (MEMBER_LAB.MEMBER_TYPE) (COMMON_LOOKUP_LAB.COMMON_LOOKUP_LAB_ID) FK_MEMBER_LAB_2 REFERENCES (MEMBER_LAB.CREDIT_CARD_TYPE) (COMMON_LOOKUP_LAB.COMMON_LOOKUP_LAB_ID) FK_MEMBER_LAB_3 REFERENCES (MEMBER_LAB.CREATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) FK_MEMBER_LAB_4 REFERENCES (MEMBER_LAB.LAST_UPDATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) |
You should then create a MEMBER_N1 non-unique index on the CREDIT_CARD_TYPE column of the MEMBER table:
COLUMN sequence_name FORMAT A22 HEADING "Sequence Name" COLUMN column_position FORMAT 999 HEADING "Column|Position" COLUMN column_name FORMAT A22 HEADING "Column|Name" SELECT ui.index_name , uic.column_position , uic.column_name FROM user_indexes ui INNER JOIN user_ind_columns uic ON ui.index_name = uic.index_name AND ui.table_name = uic.table_name WHERE ui.table_name = UPPER('member_lab') AND NOT ui.index_name IN (SELECT constraint_name FROM user_constraints) ORDER BY ui.index_name , uic.column_position; |
It should display:
COLUMN COLUMN INDEX Name POSITION Name -------------------- -------- ---------------------- MEMBER_LAB_N1 1 CREDIT_CARD_TYPE |
You can verify the existence of the MEMBER_LAB_S1 sequence with the following query:
COLUMN sequence_name FORMAT A20 HEADING "Sequence Name" SELECT sequence_name FROM user_sequences WHERE sequence_name = UPPER('member_lab_s1'); |
It should display the following:
Sequence Name -------------------- MEMBER_LAB_S1 |
- [2 points] Create the
CONTACT_LABtable described by the following and theCONTACT_LAB_S1sequence starting with a value of1001:
Instruction Details ↓
| Table Name: CONTACT_LAB | |||||
|---|---|---|---|---|---|
| Column Name | Constraint | Data Type |
Physical Size |
||
| Type | Reference Table | Reference Column | |||
| CONTACT_LAB_ID | PRIMARY KEY | Integer | Maximum | ||
| MEMBER_LAB_ID | FOREIGN KEY | MEMBER_LAB | MEMBER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| CONTACT_TYPE | FOREIGN KEY | COMMON_LOOKUP_LAB | COMMON_LOOKUP_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| LAST_NAME | NOT NULL | String | 20 | ||
| FIRST_NAME | NOT NULL | String | 20 | ||
| MIDDLE_NAME | String | 20 | |||
| CREATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| CREATION_DATE | NOT NULL | DATE | Date | ||
| LAST_UPDATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| LAST_UPDATE_DATE | NOT NULL | DATE | Date | ||
You should use the following formatting and query to verify completion of this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | SET NULL '' COLUMN table_name FORMAT A18 COLUMN column_id FORMAT 9999 COLUMN column_name FORMAT A22 COLUMN data_type FORMAT A12 SELECT table_name , column_id , column_name , CASE WHEN nullable = 'N' THEN 'NOT NULL' ELSE '' END AS nullable , CASE WHEN data_type IN ('CHAR','VARCHAR2','NUMBER') THEN data_type||'('||data_length||')' ELSE data_type END AS data_type FROM user_tab_columns WHERE table_name = 'CONTACT_LAB' ORDER BY 2; |
It should display the following results:
TABLE_NAME COLUMN_ID Name NULLABLE DATA_TYPE ------------------ --------- ---------------------- -------- ------------ CONTACT_LAB 1 CONTACT_LAB_ID NOT NULL NUMBER(22) CONTACT_LAB 2 MEMBER_LAB_ID NOT NULL NUMBER(22) CONTACT_LAB 3 CONTACT_TYPE NOT NULL NUMBER(22) CONTACT_LAB 4 FIRST_NAME NOT NULL VARCHAR2(20) CONTACT_LAB 5 MIDDLE_NAME VARCHAR2(20) CONTACT_LAB 6 LAST_NAME NOT NULL VARCHAR2(20) CONTACT_LAB 7 CREATED_BY NOT NULL NUMBER(22) CONTACT_LAB 8 CREATION_DATE NOT NULL DATE CONTACT_LAB 9 LAST_UPDATED_BY NOT NULL NUMBER(22) CONTACT_LAB 10 LAST_UPDATE_DATE NOT NULL DATE 10 rows selected. |
You should use the following formatting and query to verify completion of the constraints for this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 | COLUMN constraint_name FORMAT A22 COLUMN search_condition FORMAT A36 COLUMN constraint_type FORMAT A1 SELECT uc.constraint_name , uc.search_condition , uc.constraint_type FROM user_constraints uc INNER JOIN user_cons_columns ucc ON uc.table_name = ucc.table_name AND uc.constraint_name = ucc.constraint_name WHERE uc.table_name = UPPER('contact_lab') AND uc.constraint_type IN (UPPER('c'),UPPER('p')) ORDER BY uc.constraint_type DESC , uc.constraint_name; |
It should display the following results:
CONSTRAINT_NAME SEARCH_CONDITION C ---------------------- ------------------------------------ - PK_CONTACT_LAB_1 P NN_CONTACT_LAB_1 "MEMBER_LAB_ID" IS NOT NULL C NN_CONTACT_LAB_2 "CONTACT_TYPE" IS NOT NULL C NN_CONTACT_LAB_3 "FIRST_NAME" IS NOT NULL C NN_CONTACT_LAB_4 "LAST_NAME" IS NOT NULL C NN_CONTACT_LAB_5 "CREATED_BY" IS NOT NULL C NN_CONTACT_LAB_6 "CREATION_DATE" IS NOT NULL C NN_CONTACT_LAB_7 "LAST_UPDATED_BY" IS NOT NULL C NN_CONTACT_LAB_8 "LAST_UPDATE_DATE" IS NOT NULL C 9 rows selected. |
You can validate that you created the two foreign key constraints with the following query:
COL constraint_source FORMAT A38 HEADING "Constraint Name:| Table.Column" COL references_column FORMAT A40 HEADING "References:| Table.Column" SELECT uc.constraint_name||CHR(10) || '('||ucc1.table_name||'.'||ucc1.column_name||')' constraint_source , 'REFERENCES'||CHR(10) || '('||ucc2.table_name||'.'||ucc2.column_name||')' references_column FROM user_constraints uc , user_cons_columns ucc1 , user_cons_columns ucc2 WHERE uc.constraint_name = ucc1.constraint_name AND uc.r_constraint_name = ucc2.constraint_name AND ucc1.POSITION = ucc2.POSITION -- Correction for multiple column primary keys. AND uc.constraint_type = 'R' AND ucc1.table_name = 'CONTACT_LAB' ORDER BY ucc1.table_name , uc.constraint_name; |
It should display only the following:
Constraint Name: References: Table.Column Table.Column -------------------------------------- ----------------------------------------- FK_CONTACT_LAB_1 REFERENCES (CONTACT_LAB.MEMBER_ID) (MEMBER_LAB.MEMBER_LAB_ID) FK_CONTACT_LAB_2 REFERENCES (CONTACT_LAB.CONTACT_TYPE) (COMMON_LOOKUP_LAB.COMMON_LOOKUP_LAB_ID) FK_CONTACT_LAB_3 REFERENCES (CONTACT_LAB.CREATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) FK_CONTACT_LAB_4 REFERENCES (CONTACT_LAB.LAST_UPDATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) |
You should then create a CONTACT_N1 non-unique index on the MEMBER_ID column of the CONTACT table, and a CONTACT_N2 non-unique index on the CONTACT_TYPE
column of the CONTACT table:
COLUMN sequence_name FORMAT A22 HEADING "Sequence Name" COLUMN column_position FORMAT 999 HEADING "Column|Position" COLUMN column_name FORMAT A22 HEADING "Column|Name" SELECT ui.index_name , uic.column_position , uic.column_name FROM user_indexes ui INNER JOIN user_ind_columns uic ON ui.index_name = uic.index_name AND ui.table_name = uic.table_name WHERE ui.table_name = UPPER('contact_lab') AND NOT ui.index_name IN (SELECT constraint_name FROM user_constraints) ORDER BY ui.index_name , uic.column_position; |
It should display:
COLUMN COLUMN INDEX Name POSITION Name -------------------- -------- ---------------------- CONTACT_LAB_N1 1 MEMBER_LAB_ID CONTACT_LAB_N2 1 CONTACT_TYPE |
You can verify the existence of the CONTACT_LAB_S1 sequence with the following query:
COLUMN sequence_name FORMAT A20 HEADING "Sequence Name" SELECT sequence_name FROM user_sequences WHERE sequence_name = UPPER('contact_lab_s1'); |
It should display the following:
Sequence Name -------------------- CONTACT_LAB_S1 |
- [2 points] Create the
ADDRESS_LABtable described by the following and theADDRESS_LAB_S1sequence starting with a value of1001:
Instruction Details ↓
| Table Name: ADDRESS_LAB | |||||
|---|---|---|---|---|---|
| Column Name | Constraint | Data Type |
Physical Size |
||
| Type | Reference Table | Reference Column | |||
| ADDRESS_LAB_ID | PRIMARY KEY | Integer | Maximum | ||
| CONTACT_LAB_ID | FOREIGN KEY | CONTACT_LAB | CONTACT_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| ADDRESS_TYPE | FOREIGN KEY | COMMON_LOOKUP_LAB | COMMON_LOOKUP_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| CITY | NOT NULL | String | 30 | ||
| STATE_PROVINCE | NOT NULL | String | 30 | ||
| POSTAL_CODE | NOT NULL | String | 20 | ||
| CREATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| CREATION_DATE | NOT NULL | DATE | Date | ||
| LAST_UPDATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| LAST_UPDATE_DATE | NOT NULL | DATE | Date | ||
You should use the following formatting and query to verify completion of this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | SET NULL '' COLUMN table_name FORMAT A18 COLUMN column_id FORMAT 9999 COLUMN column_name FORMAT A22 COLUMN data_type FORMAT A12 SELECT table_name , column_id , column_name , CASE WHEN nullable = 'N' THEN 'NOT NULL' ELSE '' END AS nullable , CASE WHEN data_type IN ('CHAR','VARCHAR2','NUMBER') THEN data_type||'('||data_length||')' ELSE data_type END AS data_type FROM user_tab_columns WHERE table_name = 'ADDRESS_LAB' ORDER BY 2; |
It should display the following results:
Column TABLE_NAME COLUMN_ID Name NULLABLE DATA_TYPE ------------------ --------- ---------------------- -------- ------------ ADDRESS_LAB 1 ADDRESS_LAB_ID NOT NULL NUMBER(22) ADDRESS_LAB 2 CONTACT_LAB_ID NOT NULL NUMBER(22) ADDRESS_LAB 3 ADDRESS_TYPE NOT NULL NUMBER(22) ADDRESS_LAB 4 CITY NOT NULL VARCHAR2(30) ADDRESS_LAB 5 STATE_PROVINCE NOT NULL VARCHAR2(30) ADDRESS_LAB 6 POSTAL_CODE NOT NULL VARCHAR2(20) ADDRESS_LAB 7 CREATED_BY NOT NULL NUMBER(22) ADDRESS_LAB 8 CREATION_DATE NOT NULL DATE ADDRESS_LAB 9 LAST_UPDATED_BY NOT NULL NUMBER(22) ADDRESS_LAB 10 LAST_UPDATE_DATE NOT NULL DATE 10 rows selected. |
You should use the following formatting and query to verify completion of the constraints for this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 | COLUMN constraint_name FORMAT A22 COLUMN search_condition FORMAT A36 COLUMN constraint_type FORMAT A1 SELECT uc.constraint_name , uc.search_condition , uc.constraint_type FROM user_constraints uc INNER JOIN user_cons_columns ucc ON uc.table_name = ucc.table_name AND uc.constraint_name = ucc.constraint_name WHERE uc.table_name = UPPER('address_lab') AND uc.constraint_type IN (UPPER('c'),UPPER('p')) ORDER BY uc.constraint_type DESC , uc.constraint_name; |
It should display the following results:
CONSTRAINT_NAME SEARCH_CONDITION C ---------------------- ------------------------------------ - PK_ADDRESS_LAB_1 P NN_ADDRESS_LAB_1 "CONTACT_LAB_ID" IS NOT NULL C NN_ADDRESS_LAB_2 "ADDRESS_TYPE" IS NOT NULL C NN_ADDRESS_LAB_3 "CITY" IS NOT NULL C NN_ADDRESS_LAB_4 "STATE_PROVINCE" IS NOT NULL C NN_ADDRESS_LAB_5 "POSTAL_CODE" IS NOT NULL C NN_ADDRESS_LAB_6 "CREATED_BY" IS NOT NULL C NN_ADDRESS_LAB_7 "CREATION_DATE" IS NOT NULL C NN_ADDRESS_LAB_8 "LAST_UPDATED_BY" IS NOT NULL C NN_ADDRESS_LAB_9 "LAST_UPDATE_DATE" IS NOT NULL C 10 rows selected. |
You can validate that you created the two foreign key constraints with the following query:
COL constraint_source FORMAT A38 HEADING "Constraint Name:| Table.Column" COL references_column FORMAT A40 HEADING "References:| Table.Column" SELECT uc.constraint_name||CHR(10) || '('||ucc1.table_name||'.'||ucc1.column_name||')' constraint_source , 'REFERENCES'||CHR(10) || '('||ucc2.table_name||'.'||ucc2.column_name||')' references_column FROM user_constraints uc , user_cons_columns ucc1 , user_cons_columns ucc2 WHERE uc.constraint_name = ucc1.constraint_name AND uc.r_constraint_name = ucc2.constraint_name AND ucc1.POSITION = ucc2.POSITION -- Correction for multiple column primary keys. AND uc.constraint_type = 'R' AND ucc1.table_name = 'ADDRESS_LAB' ORDER BY ucc1.table_name , uc.constraint_name; |
It should display only the following:
Constraint Name: References: Table.Column Table.Column -------------------------------------- -------------------------------------- FK_ADDRESS_LAB_1 REFERENCES (ADDRESS_LAB.CONTACT_ID) (CONTACT_LAB.CONTACT_LAB_ID) FK_ADDRESS_LAB_2 REFERENCES (ADDRESS_LAB.ADDRESS_TYPE) (COMMON_LOOKUP_LAB.COMMON_LOOKUP_LAB_ID) FK_ADDRESS_LAB_3 REFERENCES (ADDRESS_LAB.CREATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) FK_ADDRESS_LAB_4 REFERENCES (ADDRESS_LAB.LAST_UPDATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) |
You should then create a ADDRESS_LAB_N1 non-unique index on the CONTACT_ID column of the ADDRESS_LAB table, and a CONTACT_N2 non-unique index on the ADDRESS_TYPE
column of the ADDRESS_LAB table:
COLUMN sequence_name FORMAT A22 HEADING "Sequence Name" COLUMN column_position FORMAT 999 HEADING "Column|Position" COLUMN column_name FORMAT A22 HEADING "Column|Name" SELECT ui.index_name , uic.column_position , uic.column_name FROM user_indexes ui INNER JOIN user_ind_columns uic ON ui.index_name = uic.index_name AND ui.table_name = uic.table_name WHERE ui.table_name = UPPER('address_lab') AND NOT ui.index_name IN (SELECT constraint_name FROM user_constraints) ORDER BY ui.index_name , uic.column_position; |
It should display:
COLUMN COLUMN INDEX Name POSITION Name -------------------- -------- ---------------------- ADDRESS_LAB_N1 1 CONTACT_LAB_ID ADDRESS_LAB_N2 1 ADDRESS_TYPE |
You can verify the existence of the ADDRESS_LAB_S1 sequence with the following query:
COLUMN sequence_name FORMAT A20 HEADING "Sequence Name" SELECT sequence_name FROM user_sequences WHERE sequence_name = UPPER('address_lab_s1'); |
It should display the following:
Sequence Name -------------------- ADDRESS_LAB_S1 |
- [2 points] Create the
STREET_ADDRESS_LABtable described by the following and theSTREET_ADDRESS_LAB_S1sequence starting with a value of1001:
Instruction Details ↓
| Table Name: STREET_ADDRESS_LAB | |||||
|---|---|---|---|---|---|
| Column Name | Constraint | Data Type |
Physical Size |
||
| Type | Reference Table | Reference Column | |||
| STREET_ADDRESS_LAB_ID | PRIMARY KEY | Integer | Maximum | ||
| ADDRESS_LAB_ID | FOREIGN KEY | ADDRESS_LAB | ADDRESS_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| STREET_ADDRESS | NOT NULL | String | 30 | ||
| CREATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| CREATION_DATE | NOT NULL | DATE | Date | ||
| LAST_UPDATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| LAST_UPDATE_DATE | NOT NULL | DATE | Date | ||
You should use the following formatting and query to verify completion of this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | SET NULL '' COLUMN table_name FORMAT A18 COLUMN column_id FORMAT 9999 COLUMN column_name FORMAT A22 COLUMN data_type FORMAT A12 SELECT table_name , column_id , column_name , CASE WHEN nullable = 'N' THEN 'NOT NULL' ELSE '' END AS nullable , CASE WHEN data_type IN ('CHAR','VARCHAR2','NUMBER') THEN data_type||'('||data_length||')' ELSE data_type END AS data_type FROM user_tab_columns WHERE table_name = 'STREET_ADDRESS_LAB' ORDER BY 2; |
It should display the following results:
TABLE_NAME COLUMN_ID Name NULLABLE DATA_TYPE ------------------ --------- ---------------------- -------- ------------ STREET_ADDRESS_LAB 1 STREET_ADDRESS_LAB_ID NOT NULL NUMBER(22) STREET_ADDRESS_LAB 2 STREET_ADDRESS NOT NULL VARCHAR2(30) STREET_ADDRESS_LAB 3 CREATED_BY NOT NULL NUMBER(22) STREET_ADDRESS_LAB 4 CREATION_DATE NOT NULL DATE STREET_ADDRESS_LAB 5 LAST_UPDATED_BY NOT NULL NUMBER(22) STREET_ADDRESS_LAB 6 LAST_UPDATE_DATE NOT NULL DATE 6 rows selected. |
You should use the following formatting and query to verify completion of the constraints for this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 | COLUMN constraint_name FORMAT A22 COLUMN search_condition FORMAT A36 COLUMN constraint_type FORMAT A1 SELECT uc.constraint_name , uc.search_condition , uc.constraint_type FROM user_constraints uc INNER JOIN user_cons_columns ucc ON uc.table_name = ucc.table_name AND uc.constraint_name = ucc.constraint_name WHERE uc.table_name = UPPER('street_address_lab') AND uc.constraint_type IN (UPPER('c'),UPPER('p')) ORDER BY uc.constraint_type DESC , uc.constraint_name; |
It should display the following results:
CONSTRAINT_NAME SEARCH_CONDITION C ---------------------- ------------------------------------ - PK_SADDRESS_LAB_1 P NN_SADDRESS_LAB_1 "ADDRESS_ID" IS NOT NULL C NN_SADDRESS_LAB_2 "STREET_ADDRESS" IS NOT NULL C NN_SADDRESS_LAB_3 "CREATED_BY" IS NOT NULL C NN_SADDRESS_LAB_4 "CREATION_DATE" IS NOT NULL C NN_SADDRESS_LAB_5 "LAST_UPDATED_BY" IS NOT NULL C NN_SADDRESS_LAB_6 "LAST_UPDATE_DATE" IS NOT NULL C 7 rows selected. |
You can validate that you created the two foreign key constraints with the following query:
COL constraint_source FORMAT A38 HEADING "Constraint Name:| Table.Column" COL references_column FORMAT A40 HEADING "References:| Table.Column" SELECT uc.constraint_name||CHR(10) || '('||ucc1.table_name||'.'||ucc1.column_name||')' constraint_source , 'REFERENCES'||CHR(10) || '('||ucc2.table_name||'.'||ucc2.column_name||')' references_column FROM user_constraints uc , user_cons_columns ucc1 , user_cons_columns ucc2 WHERE uc.constraint_name = ucc1.constraint_name AND uc.r_constraint_name = ucc2.constraint_name AND ucc1.POSITION = ucc2.POSITION -- Correction for multiple column primary keys. AND uc.constraint_type = 'R' AND ucc1.table_name = UPPER('street_address_lab') ORDER BY ucc1.table_name , uc.constraint_name; |
It should display only the following:
Constraint Name: References: Table.Column Table.Column -------------------------------------- ---------------------------------------- FK_SADDRESS_LAB_1 REFERENCES (STREET_ADDRESS_LAB.ADDRESS_LAB_ID) (ADDRESS_LAB.ADDRESS_LAB_ID) FK_SADDRESS_LAB_2 REFERENCES (STREET_ADDRESS_LAB.CREATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) FK_SADDRESS_LAB_3 REFERENCES (STREET_ADDRESS_LAB.LAST_UPDATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) |
You can verify the existence of the STREET_ADDRESS_LAB_S1 sequence with the following query:
COLUMN sequence_name FORMAT A22 HEADING "Sequence Name" SELECT sequence_name FROM user_sequences WHERE sequence_name = UPPER('street_address_lab_s1'); |
It should display the following:
Sequence Name ---------------------- STREET_ADDRESS_LAB_S1 |
- [2 points] Create the
TELEPHONE_LABtable described by the following and theTELEPHONE_LAB_S1sequence starting with a value of1001:
Instruction Details ↓
| Table Name: TELEPHONE_LAB | |||||
|---|---|---|---|---|---|
| Column Name | Constraint | Data Type |
Physical Size |
||
| Type | Reference Table | Reference Column | |||
| TELEPHONE_LAB_ID | PRIMARY KEY | Integer | Maximum | ||
| CONTACT_LAB_ID | FOREIGN KEY | CONTACT_LAB | CONTACT_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| ADDRESS_LAB_ID | FOREIGN KEY | ADDRESS_LAB | ADDRESS_LAB_ID | Integer | Maximum |
| TELEPHONE_TYPE | FOREIGN KEY | COMMON_LOOKUP_LAB | COMMON_LOOKUP_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| COUNTRY_CODE | NOT NULL | String | 3 | ||
| AREA_CODE | NOT NULL | String | 6 | ||
| TELEPHONE_NUMBER | NOT NULL | String | 10 | ||
| CREATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| CREATION_DATE | NOT NULL | DATE | Date | ||
| LAST_UPDATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| LAST_UPDATE_DATE | NOT NULL | DATE | Date | ||
You should use the following formatting and query to verify completion of this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | SET NULL '' COLUMN table_name FORMAT A18 COLUMN column_id FORMAT 9999 COLUMN column_name FORMAT A22 COLUMN data_type FORMAT A12 SELECT table_name , column_id , column_name , CASE WHEN nullable = 'N' THEN 'NOT NULL' ELSE '' END AS nullable , CASE WHEN data_type IN ('CHAR','VARCHAR2','NUMBER') THEN data_type||'('||data_length||')' ELSE data_type END AS data_type FROM user_tab_columns WHERE table_name = 'TELEPHONE_LAB' ORDER BY 2; |
It should display the following results:
Column TABLE_NAME COLUMN_ID Name NULLABLE DATA_TYPE ------------------ --------- ---------------------- -------- ------------ TELEPHONE_LAB 1 TELEPHONE_LAB_ID NOT NULL NUMBER(22) TELEPHONE_LAB 2 CONTACT_LAB_ID NOT NULL NUMBER(22) TELEPHONE_LAB 3 ADDRESS_LAB_ID NUMBER(22) TELEPHONE_LAB 4 TELEPHONE_TYPE NOT NULL NUMBER(22) TELEPHONE_LAB 5 COUNTRY_CODE NOT NULL VARCHAR2(3) TELEPHONE_LAB 6 AREA_CODE NOT NULL VARCHAR2(6) TELEPHONE_LAB 7 TELEPHONE_NUMBER NOT NULL VARCHAR2(10) TELEPHONE_LAB 8 CREATED_BY NOT NULL NUMBER(22) TELEPHONE_LAB 9 CREATION_DATE NOT NULL DATE TELEPHONE_LAB 10 LAST_UPDATED_BY NOT NULL NUMBER(22) TELEPHONE_LAB 11 LAST_UPDATE_DATE NOT NULL DATE 11 rows selected. |
You should use the following formatting and query to verify completion of the constraints for this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 | COLUMN constraint_name FORMAT A22 COLUMN search_condition FORMAT A36 COLUMN constraint_type FORMAT A1 SELECT uc.constraint_name , uc.search_condition , uc.constraint_type FROM user_constraints uc INNER JOIN user_cons_columns ucc ON uc.table_name = ucc.table_name AND uc.constraint_name = ucc.constraint_name WHERE uc.table_name = UPPER('telephone_lab') AND uc.constraint_type IN (UPPER('c'),UPPER('p')) ORDER BY uc.constraint_type DESC , uc.constraint_name; |
It should display the following results:
CONSTRAINT_NAME SEARCH_CONDITION C ---------------------- ------------------------------------ - PK_TELEPHONE_LAB_1 P NN_TELEPHONE_LAB_1 "CONTACT_ID" IS NOT NULL C NN_TELEPHONE_LAB_2 "TELEPHONE_TYPE" IS NOT NULL C NN_TELEPHONE_LAB_3 "COUNTRY_CODE" IS NOT NULL C NN_TELEPHONE_LAB_4 "AREA_CODE" IS NOT NULL C NN_TELEPHONE_LAB_5 "TELEPHONE_NUMBER" IS NOT NULL C NN_TELEPHONE_LAB_6 "CREATED_BY" IS NOT NULL C NN_TELEPHONE_LAB_7 "CREATION_DATE" IS NOT NULL C NN_TELEPHONE_LAB_8 "LAST_UPDATED_BY" IS NOT NULL C NN_TELEPHONE_LAB_9 "LAST_UPDATE_DATE" IS NOT NULL C 10 rows selected. |
You can validate that you created the two foreign key constraints with the following query:
COL constraint_source FORMAT A38 HEADING "Constraint Name:| Table.Column" COL references_column FORMAT A40 HEADING "References:| Table.Column" SELECT uc.constraint_name||CHR(10) || '('||ucc1.table_name||'.'||ucc1.column_name||')' constraint_source , 'REFERENCES'||CHR(10) || '('||ucc2.table_name||'.'||ucc2.column_name||')' references_column FROM user_constraints uc , user_cons_columns ucc1 , user_cons_columns ucc2 WHERE uc.constraint_name = ucc1.constraint_name AND uc.r_constraint_name = ucc2.constraint_name AND ucc1.POSITION = ucc2.POSITION -- Correction for multiple column primary keys. AND uc.constraint_type = 'R' AND ucc1.table_name = UPPER('telephone_lab') ORDER BY ucc1.table_name , uc.constraint_name; |
It should display only the following:
Constraint Name: References: Table.Column Table.Column -------------------------------------- -------------------------------------- FK_TELEPHONE_LAB_1 REFERENCES (TELEPHONE_LAB.CONTACT_LAB_ID) (CONTACT_LAB.CONTACT_LAB_ID) FK_TELEPHONE_LAB_2 REFERENCES (TELEPHONE_LAB.TELEPHONE_TYPE) (COMMON_LOOKUP_LAB.COMMON_LOOKUP_LAB_ID) FK_TELEPHONE_LAB_3 REFERENCES (TELEPHONE_LAB.CREATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) FK_TELEPHONE_LAB_4 REFERENCES (TELEPHONE_LAB.LAST_UPDATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) |
You should then create a TELEPHONE_LAB_N1 non-unique index on the CONTACT_ID and ADDRESS_ID columns of the TELEPHONE_LAB table, a TELEPHONE_N2 non-unique index on the ADDRESS_ID column of the TELEPHONE_LAB table, and a TELEPHONE_N3 non-unique index on the TELEPHONE_TYPE column of the TELEPHONE_LAB table:
COLUMN sequence_name FORMAT A22 HEADING "Sequence Name" COLUMN column_position FORMAT 999 HEADING "Column|Position" COLUMN column_name FORMAT A22 HEADING "Column|Name" SELECT ui.index_name , uic.column_position , uic.column_name FROM user_indexes ui INNER JOIN user_ind_columns uic ON ui.index_name = uic.index_name AND ui.table_name = uic.table_name WHERE ui.table_name = UPPER('telephone_lab') AND NOT ui.index_name IN (SELECT constraint_name FROM user_constraints) ORDER BY ui.index_name , uic.column_position; |
It should display:
COLUMN COLUMN INDEX Name POSITION Name -------------------- -------- ---------------------- TELEPHONE_LAB_N1 1 CONTACT_LAB_ID TELEPHONE_LAB_N1 2 ADDRESS_LAB_ID TELEPHONE_LAB_N2 1 ADDRESS_LAB_ID TELEPHONE_LAB_N3 1 TELEPHONE_TYPE |
You can verify the existence of the TELEPHONE_LAB_S1 sequence with the following query:
COLUMN sequence_name FORMAT A20 HEADING "Sequence Name" SELECT sequence_name FROM user_sequences WHERE sequence_name = UPPER('telephone_lab_s1'); |
It should display the following:
Sequence Name -------------------- TELEPHONE_LAB_S1 |
- [2 points] Create the
RENTAL_LABtable described by the following and theRENTAL_LAB_S1sequence starting with a value of1001:
Instruction Details ↓
| Table Name: RENTAL_LAB | |||||
|---|---|---|---|---|---|
| Column Name | Constraint | Data Type |
Physical Size |
||
| Type | Reference Table | Reference Column | |||
| RENTAL_LAB_ID | PRIMARY KEY | Integer | Maximum | ||
| CUSTOMER_ID | FOREIGN KEY | CONTACT_LAB | CONTACT_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| CHECK_OUT_DATE | NOT NULL | DATE | Date | ||
| RETURN_DATE | NOT NULL | DATE | Date | ||
| CREATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| CREATION_DATE | NOT NULL | DATE | Date | ||
| LAST_UPDATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| LAST_UPDATE_DATE | NOT NULL | DATE | Date | ||
You should use the following formatting and query to verify completion of this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | SET NULL '' COLUMN table_name FORMAT A18 COLUMN column_id FORMAT 9999 COLUMN column_name FORMAT A22 COLUMN data_type FORMAT A12 SELECT table_name , column_id , column_name , CASE WHEN nullable = 'N' THEN 'NOT NULL' ELSE '' END AS nullable , CASE WHEN data_type IN ('CHAR','VARCHAR2','NUMBER') THEN data_type||'('||data_length||')' ELSE data_type END AS data_type FROM user_tab_columns WHERE table_name = UPPER('rental_lab') ORDER BY 2; |
It should display the following results:
Column TABLE_NAME COLUMN_ID Name NULLABLE DATA_TYPE ------------------ --------- ---------------------- -------- ------------ RENTAL_LAB 1 RENTAL_LAB_ID NOT NULL NUMBER(22) RENTAL_LAB 2 CUSTOMER_ID NOT NULL NUMBER(22) RENTAL_LAB 3 CHECK_OUT_DATE NOT NULL DATE RENTAL_LAB 4 RETURN_DATE NOT NULL DATE RENTAL_LAB 5 CREATED_BY NOT NULL NUMBER(22) RENTAL_LAB 6 CREATION_DATE NOT NULL DATE RENTAL_LAB 7 LAST_UPDATED_BY NOT NULL NUMBER(22) RENTAL_LAB 8 LAST_UPDATE_DATE NOT NULL DATE 8 rows selected. |
You should use the following formatting and query to verify completion of the constraints for this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 | COLUMN constraint_name FORMAT A22 COLUMN search_condition FORMAT A36 COLUMN constraint_type FORMAT A1 SELECT uc.constraint_name , uc.search_condition , uc.constraint_type FROM user_constraints uc INNER JOIN user_cons_columns ucc ON uc.table_name = ucc.table_name AND uc.constraint_name = ucc.constraint_name WHERE uc.table_name = UPPER('rental_lab') AND uc.constraint_type IN (UPPER('c'),UPPER('p')) ORDER BY uc.constraint_type DESC , uc.constraint_name; |
It should display the following results:
CONSTRAINT_NAME SEARCH_CONDITION C ---------------------- ------------------------------------ - PK_RENTAL_LAB_1 P NN_RENTAL_LAB_1 "CUSTOMER_ID" IS NOT NULL C NN_RENTAL_LAB_2 "CHECK_OUT_DATE" IS NOT NULL C NN_RENTAL_LAB_3 "RETURN_DATE" IS NOT NULL C NN_RENTAL_LAB_4 "CREATED_BY" IS NOT NULL C NN_RENTAL_LAB_5 "CREATION_DATE" IS NOT NULL C NN_RENTAL_LAB_6 "LAST_UPDATED_BY" IS NOT NULL C NN_RENTAL_LAB_7 "LAST_UPDATE_DATE" IS NOT NULL C 8 rows selected. |
You can validate that you created the two foreign key constraints with the following query:
COL constraint_source FORMAT A38 HEADING "Constraint Name:| Table.Column" COL references_column FORMAT A40 HEADING "References:| Table.Column" SELECT uc.constraint_name||CHR(10) || '('||ucc1.table_name||'.'||ucc1.column_name||')' constraint_source , 'REFERENCES'||CHR(10) || '('||ucc2.table_name||'.'||ucc2.column_name||')' references_column FROM user_constraints uc , user_cons_columns ucc1 , user_cons_columns ucc2 WHERE uc.constraint_name = ucc1.constraint_name AND uc.r_constraint_name = ucc2.constraint_name AND ucc1.POSITION = ucc2.POSITION -- Correction for multiple column primary keys. AND uc.constraint_type = 'R' AND ucc1.table_name = UPPER('rental_lab') ORDER BY ucc1.table_name , uc.constraint_name; |
It should display only the following:
Constraint Name: References: Table.Column Table.Column -------------------------------------- ---------------------------------------- FK_RENTAL_LAB_1 REFERENCES (RENTAL_LAB.CUSTOMER_ID) (CONTACT_LAB.CONTACT_LAB_ID) FK_RENTAL_LAB_2 REFERENCES (RENTAL_LAB.CREATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) FK_RENTAL_LAB_3 REFERENCES (RENTAL_LAB.LAST_UPDATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) |
You can verify the existence of the RENTAL_LAB_S1 sequence with the following query:
COLUMN sequence_name FORMAT A20 HEADING "Sequence Name" SELECT sequence_name FROM user_sequences WHERE sequence_name = UPPER('rental_lab_s1'); |
It should display the following:
Sequence Name -------------------- RENTAL_LAB_S1 |
- [2 points] Create the
ITEM_LABtable described by the following and theITEM_LAB_S1sequence starting with a value of1001:
Instruction Details ↓
| Table Name: ITEM_LAB | |||||
|---|---|---|---|---|---|
| Column Name | Constraint | Data Type |
Physical Size |
||
| Type | Reference Table | Reference Column | |||
| ITEM_LAB_ID | PRIMARY KEY | Integer | Maximum | ||
| ITEM_BARCODE | NOT NULL | String | 14 | ||
| ITEM_TYPE | FOREIGN KEY | COMMON_LOOKUP_LAB | COMMON_LOOKUP_ID | Integer | Maximum |
| NOT NULL | |||||
| ITEM_TITLE | NOT NULL | String | 60 | ||
| ITEM_SUBTITLE | String | 60 | |||
| ITEM_RATING | NOT NULL | String | 8 | ||
| ITEM_RELEASE_DATE | NOT NULL | DATE | Date | ||
| CREATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| CREATION_DATE | NOT NULL | DATE | Date | ||
| LAST_UPDATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| LAST_UPDATE_DATE | NOT NULL | DATE | Date | ||
You should use the following formatting and query to verify completion of this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | SET NULL '' COLUMN table_name FORMAT A18 COLUMN column_id FORMAT 9999 COLUMN column_name FORMAT A22 COLUMN data_type FORMAT A12 SELECT table_name , column_id , column_name , CASE WHEN nullable = 'N' THEN 'NOT NULL' ELSE '' END AS nullable , CASE WHEN data_type IN ('CHAR','VARCHAR2','NUMBER') THEN data_type||'('||data_length||')' ELSE data_type END AS data_type FROM user_tab_columns WHERE table_name = 'ITEM_LAB' ORDER BY 2; |
It should display the following results:
Column TABLE_NAME COLUMN_ID Name NULLABLE DATA_TYPE ------------------ --------- ---------------------- -------- ------------ ITEM_LAB 1 ITEM_LAB_ID NOT NULL NUMBER(22) ITEM_LAB 2 ITEM_BARCODE NOT NULL VARCHAR2(14) ITEM_LAB 3 ITEM_TYPE NOT NULL NUMBER(22) ITEM_LAB 4 ITEM_TITLE NOT NULL VARCHAR2(60) ITEM_LAB 5 ITEM_SUBTITLE VARCHAR2(60) ITEM_LAB 6 ITEM_RATING NOT NULL VARCHAR2(8) ITEM_LAB 7 ITEM_RELEASE_DATE NOT NULL DATE ITEM_LAB 8 CREATED_BY NOT NULL NUMBER(22) ITEM_LAB 9 CREATION_DATE NOT NULL DATE ITEM_LAB 10 LAST_UPDATED_BY NOT NULL NUMBER(22) ITEM_LAB 11 LAST_UPDATE_DATE NOT NULL DATE 11 rows selected. |
You should use the following formatting and query to verify completion of the constraints for this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 | COLUMN constraint_name FORMAT A22 COLUMN search_condition FORMAT A36 COLUMN constraint_type FORMAT A1 SELECT uc.constraint_name , uc.search_condition , uc.constraint_type FROM user_constraints uc INNER JOIN user_cons_columns ucc ON uc.table_name = ucc.table_name AND uc.constraint_name = ucc.constraint_name WHERE uc.table_name = UPPER('item_lab') AND uc.constraint_type IN (UPPER('c'),UPPER('p')) ORDER BY uc.constraint_type DESC , uc.constraint_name; |
It should display the following results:
CONSTRAINT_NAME SEARCH_CONDITION C ---------------------- ------------------------------------ - PK_ITEM_LAB_1 P NN_ITEM_LAB_1 "ITEM_BARCODE" IS NOT NULL C NN_ITEM_LAB_2 "ITEM_TYPE" IS NOT NULL C NN_ITEM_LAB_3 "ITEM_TITLE" IS NOT NULL C NN_ITEM_LAB_4 "ITEM_RATING" IS NOT NULL C NN_ITEM_LAB_5 "ITEM_RELEASE_DATE" IS NOT NULL C NN_ITEM_LAB_6 "CREATED_BY" IS NOT NULL C NN_ITEM_LAB_7 "CREATION_DATE" IS NOT NULL C NN_ITEM_LAB_8 "LAST_UPDATED_BY" IS NOT NULL C NN_ITEM_LAB_9 "LAST_UPDATE_DATE" IS NOT NULL C 10 rows selected. |
You can validate that you created the two foreign key constraints with the following query:
COL constraint_source FORMAT A38 HEADING "Constraint Name:| Table.Column" COL references_column FORMAT A38 HEADING "References:| Table.Column" SELECT uc.constraint_name||CHR(10) || '('||ucc1.table_name||'.'||ucc1.column_name||')' constraint_source , 'REFERENCES'||CHR(10) || '('||ucc2.table_name||'.'||ucc2.column_name||')' references_column FROM user_constraints uc , user_cons_columns ucc1 , user_cons_columns ucc2 WHERE uc.constraint_name = ucc1.constraint_name AND uc.r_constraint_name = ucc2.constraint_name AND ucc1.POSITION = ucc2.POSITION -- Correction for multiple column primary keys. AND uc.constraint_type = 'R' AND ucc1.table_name = UPPER('item_lab') ORDER BY ucc1.table_name , uc.constraint_name; |
It should display only the following:
Constraint Name: References: Table.Column Table.Column -------------------------------------- ---------------------------------------- FK_ITEM_LAB_1 REFERENCES (ITEM_LAB.ITEM_TYPE) (COMMON_LOOKUP_LAB.COMMON_LOOKUP_LAB_ID) FK_ITEM_LAB_2 REFERENCES (ITEM_LAB.CREATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) FK_ITEM_LAB_3 REFERENCES (ITEM_LAB.LAST_UPDATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) |
You can verify the existence of the ITEM_LAB_S1 sequence with the following query:
COLUMN sequence_name FORMAT A20 HEADING "Sequence Name" SELECT sequence_name FROM user_sequences WHERE sequence_name = UPPER('item_lab_s1'); |
It should display the following:
Sequence Name -------------------- ITEM_LAB_S1 |
- [2 points] Create the
RENTAL_ITEM_LABtable described by the following and theRENTAL_ITEM_LAB_S1sequence starting with a value of1001:
Instruction Details ↓
| Table Name: RENTAL_ITEM_LAB | |||||
|---|---|---|---|---|---|
| Column Name | Constraint | Data Type |
Physical Size |
||
| Type | Reference Table | Reference Column | |||
| RENTAL_ITEM_LAB_ID | PRIMARY KEY | Integer | Maximum | ||
| RENTAL_LAB_ID | FOREIGN KEY | RENTAL_LAB | RENTAL_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| ITEM_LAB_ID | FOREIGN KEY | ITEM_LAB | ITEM_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| CREATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| CREATION_DATE | NOT NULL | DATE | Date | ||
| LAST_UPDATED_BY | FOREIGN KEY | SYSTEM_USER_LAB | SYSTEM_USER_LAB_ID | Integer | Maximum |
| NOT NULL | |||||
| LAST_UPDATE_DATE | NOT NULL | DATE | Date | ||
You should use the following formatting and query to verify completion of this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | SET NULL '' COLUMN table_name FORMAT A18 COLUMN column_id FORMAT 9999 COLUMN column_name FORMAT A22 COLUMN data_type FORMAT A12 SELECT table_name , column_id , column_name , CASE WHEN nullable = 'N' THEN 'NOT NULL' ELSE '' END AS nullable , CASE WHEN data_type IN ('CHAR','VARCHAR2','NUMBER') THEN data_type||'('||data_length||')' ELSE data_type END AS data_type FROM user_tab_columns WHERE table_name = UPPER('rental_item_lab') ORDER BY 2; |
It should display the following results:
Column TABLE_NAME COLUMN_ID Name NULLABLE DATA_TYPE ------------------ --------- ---------------------- -------- ------------ RENTAL_ITEM_LAB 1 RENTAL_ITEM_LAB_ID NOT NULL NUMBER(22) RENTAL_ITEM_LAB 2 RENTAL_LAB_ID NOT NULL NUMBER(22) RENTAL_ITEM_LAB 3 ITEM_LAB_ID NOT NULL NUMBER(22) RENTAL_ITEM_LAB 4 CREATED_BY NOT NULL NUMBER(22) RENTAL_ITEM_LAB 5 CREATION_DATE NOT NULL DATE RENTAL_ITEM_LAB 6 LAST_UPDATED_BY NOT NULL NUMBER(22) RENTAL_ITEM_LAB 7 LAST_UPDATE_DATE NOT NULL DATE 7 rows selected. |
You should use the following formatting and query to verify completion of the constraints for this step:
1 2 3 4 5 6 7 8 9 10 11 12 13 | COLUMN constraint_name FORMAT A22 COLUMN search_condition FORMAT A36 COLUMN constraint_type FORMAT A1 SELECT uc.constraint_name , uc.search_condition , uc.constraint_type FROM user_constraints uc INNER JOIN user_cons_columns ucc ON uc.table_name = ucc.table_name AND uc.constraint_name = ucc.constraint_name WHERE uc.table_name = UPPER('rental_item_lab') AND uc.constraint_type IN (UPPER('c'),UPPER('p')) ORDER BY uc.constraint_type DESC , uc.constraint_name; |
It should display the following results:
CONSTRAINT_NAME SEARCH_CONDITION C ---------------------- ------------------------------------ - PK_RENTAL_ITEM_LAB_1 P NN_RENTAL_ITEM_LAB_1 "RENTAL_LAB_ID" IS NOT NULL C NN_RENTAL_ITEM_LAB_2 "ITEM_LAB_ID" IS NOT NULL C NN_RENTAL_ITEM_LAB_3 "CREATED_BY" IS NOT NULL C NN_RENTAL_ITEM_LAB_4 "CREATION_DATE" IS NOT NULL C NN_RENTAL_ITEM_LAB_5 "LAST_UPDATED_BY" IS NOT NULL C NN_RENTAL_ITEM_LAB_6 "LAST_UPDATE_DATE" IS NOT NULL C 7 rows selected. |
You can validate that you created the two foreign key constraints with the following query:
COL constraint_source FORMAT A38 HEADING "Constraint Name:| Table.Column" COL references_column FORMAT A40 HEADING "References:| Table.Column" SELECT uc.constraint_name||CHR(10) || '('||ucc1.table_name||'.'||ucc1.column_name||')' constraint_source , 'REFERENCES'||CHR(10) || '('||ucc2.table_name||'.'||ucc2.column_name||')' references_column FROM user_constraints uc , user_cons_columns ucc1 , user_cons_columns ucc2 WHERE uc.constraint_name = ucc1.constraint_name AND uc.r_constraint_name = ucc2.constraint_name AND ucc1.POSITION = ucc2.POSITION -- Correction for multiple column primary keys. AND uc.constraint_type = 'R' AND ucc1.table_name = UPPER('rental_item_lab') ORDER BY ucc1.table_name , uc.constraint_name; |
It should display only the following:
Constraint Name: References: Table.Column Table.Column -------------------------------------- ---------------------------------------- FK_RENTAL_ITEM_LAB_1 REFERENCES (RENTAL_ITEM_LAB.RENTAL_LAB_ID) (RENTAL_LAB.RENTAL_LAB_ID) FK_RENTAL_ITEM_LAB_2 REFERENCES (RENTAL_ITEM_LAB.ITEM_LAB_ID) (ITEM_LAB.ITEM_LAB_ID) FK_RENTAL_ITEM_LAB_3 REFERENCES (RENTAL_ITEM_LAB.CREATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) FK_RENTAL_ITEM_LAB_4 REFERENCES (RENTAL_ITEM_LAB.LAST_UPDATED_BY) (SYSTEM_USER_LAB.SYSTEM_USER_LAB_ID) |
You can verify the existence of the ITEM_LAB_S1 sequence with the following query:
COLUMN sequence_name FORMAT A20 HEADING "Sequence Name" SELECT sequence_name FROM user_sequences WHERE sequence_name = UPPER('rental_item_lab_s1'); |
It should display the following:
Sequence Name -------------------- RENTAL_ITEM_LAB_S1 |
- [0 points] You can confirm the creation of the ten tables with the following query:
Confirmation Details for Tables ↓
COLUMN table_name_base FORMAT A30 HEADING "Base Tables" COLUMN table_name_lab FORMAT A30 HEADING "Lab Tables" SELECT a.table_name_base , b.table_name_lab FROM (SELECT table_name AS table_name_base FROM user_tables WHERE table_name IN ('SYSTEM_USER' ,'COMMON_LOOKUP' ,'MEMBER' ,'CONTACT' ,'ADDRESS' ,'STREET_ADDRESS' ,'TELEPHONE' ,'ITEM' ,'RENTAL' ,'RENTAL_ITEM')) a INNER JOIN (SELECT table_name AS table_name_lab FROM user_tables WHERE table_name IN ('SYSTEM_USER_LAB' ,'COMMON_LOOKUP_LAB' ,'MEMBER_LAB' ,'CONTACT_LAB' ,'ADDRESS_LAB' ,'STREET_ADDRESS_LAB' ,'TELEPHONE_LAB' ,'ITEM_LAB' ,'RENTAL_LAB' ,'RENTAL_ITEM_LAB')) b ON a.table_name_base = SUBSTR( b.table_name_lab, 1, REGEXP_INSTR(table_name_lab,'_LAB') - 1) ORDER BY CASE WHEN table_name_base LIKE 'SYSTEM_USER%' THEN 0 WHEN table_name_base LIKE 'COMMON_LOOKUP%' THEN 1 WHEN table_name_base LIKE 'MEMBER%' THEN 2 WHEN table_name_base LIKE 'CONTACT%' THEN 3 WHEN table_name_base LIKE 'ADDRESS%' THEN 4 WHEN table_name_base LIKE 'STREET_ADDRESS%' THEN 5 WHEN table_name_base LIKE 'TELEPHONE%' THEN 6 WHEN table_name_base LIKE 'ITEM%' THEN 7 WHEN table_name_base LIKE 'RENTAL%' AND NOT table_name_base LIKE 'RENTAL_ITEM%' THEN 8 WHEN table_name_base LIKE 'RENTAL_ITEM%' THEN 9 END; |
It returns:
Base Tables Lab Tables ------------------------------ ------------------------------ SYSTEM_USER SYSTEM_USER_LAB COMMON_LOOKUP COMMON_LOOKUP_LAB MEMBER MEMBER_LAB CONTACT CONTACT_LAB ADDRESS ADDRESS_LAB STREET_ADDRESS STREET_ADDRESS_LAB TELEPHONE TELEPHONE_LAB ITEM ITEM_LAB RENTAL RENTAL_LAB RENTAL_ITEM RENTAL_ITEM_LAB 10 rows selected. |
- [0 points] You can confirm the creation of the ten sequences with the following query:
Confirmation Details for Sequences ↓
COLUMN sequence_name_base FORMAT A30 HEADING "Base Sequences" COLUMN sequence_name_lab FORMAT A30 HEADING "Lab Sequences" SELECT a.sequence_name_base , b.sequence_name_lab FROM (SELECT sequence_name AS sequence_name_base FROM user_sequences WHERE sequence_name IN ('SYSTEM_USER_S1' ,'COMMON_LOOKUP_S1' ,'MEMBER_S1' ,'CONTACT_S1' ,'ADDRESS_S1' ,'STREET_ADDRESS_S1' ,'TELEPHONE_S1' ,'ITEM_S1' ,'RENTAL_S1' ,'RENTAL_ITEM_S1')) a INNER JOIN (SELECT sequence_name AS sequence_name_lab FROM user_sequences WHERE sequence_name IN ('SYSTEM_USER_LAB_S1' ,'COMMON_LOOKUP_LAB_S1' ,'MEMBER_LAB_S1' ,'CONTACT_LAB_S1' ,'ADDRESS_LAB_S1' ,'STREET_ADDRESS_LAB_S1' ,'TELEPHONE_LAB_S1' ,'ITEM_LAB_S1' ,'RENTAL_LAB_S1' ,'RENTAL_ITEM_LAB_S1')) b ON SUBSTR(a.sequence_name_base, 1, REGEXP_INSTR(a.sequence_name_base,'_S1') - 1) = SUBSTR( b.sequence_name_lab, 1, REGEXP_INSTR(b.sequence_name_lab,'_LAB_S1') - 1) ORDER BY CASE WHEN sequence_name_base LIKE 'SYSTEM_USER%' THEN 0 WHEN sequence_name_base LIKE 'COMMON_LOOKUP%' THEN 1 WHEN sequence_name_base LIKE 'MEMBER%' THEN 2 WHEN sequence_name_base LIKE 'CONTACT%' THEN 3 WHEN sequence_name_base LIKE 'ADDRESS%' THEN 4 WHEN sequence_name_base LIKE 'STREET_ADDRESS%' THEN 5 WHEN sequence_name_base LIKE 'TELEPHONE%' THEN 6 WHEN sequence_name_base LIKE 'ITEM%' THEN 7 WHEN sequence_name_base LIKE 'RENTAL%' AND NOT sequence_name_base LIKE 'RENTAL_ITEM%' THEN 8 WHEN sequence_name_base LIKE 'RENTAL_ITEM%' THEN 9 END; |
It returns:
Base Sequences Lab Sequences ------------------------------ ------------------------------ SYSTEM_USER_S1 SYSTEM_USER_LAB_S1 COMMON_LOOKUP_S1 COMMON_LOOKUP_LAB_S1 MEMBER_S1 MEMBER_LAB_S1 CONTACT_S1 CONTACT_LAB_S1 ADDRESS_S1 ADDRESS_LAB_S1 STREET_ADDRESS_S1 STREET_ADDRESS_LAB_S1 TELEPHONE_S1 TELEPHONE_LAB_S1 ITEM_S1 ITEM_LAB_S1 RENTAL_S1 RENTAL_LAB_S1 RENTAL_ITEM_S1 RENTAL_ITEM_LAB_S1 10 rows selected. |